In the world of cloud-native engineering, the staging environment is often where developer velocity goes to die. For engineering leaders and platform teams, the phrase “staging is down again” has become a painful, all-too-common refrain. It signals the start of another productivity-killing investigation that grinds pull request reviews, CI/CD pipelines, and feature delivery to a halt.
This isn’t a new problem, but its scale and cost have been magnified by the very architecture designed to speed us up: microservices. The promise of microservices was team autonomy and independent, rapid deployments. The reality for many scaling organizations is a shared staging environment that has become a central bottleneck, creating a state of constant resource contention and instability.1 When multiple teams deploy concurrent, unstable features into the same shared space, a single test failure triggers a time-consuming forensic exercise. Was it my change? Was it another team’s deployment? Or is the environment itself in a broken state?
This uncertainty erodes developer confidence and slows the entire delivery pipeline. In fact, the problem of slow, inefficient testing is not just a frustration; it’s a multi-million dollar drain on resources. One VP of Platform Engineering recently calculated their “broken testing process” was costing them half a million dollars monthly in lost productivity.
This guide provides a strategic framework for engineering leaders and platform teams to navigate this challenge. We will explore the evolution of testing environments, from the inherent flaws of the traditional staging model to the rise of modern ephemeral environments. We will conduct a deep, balanced analysis of the two dominant architectural models for these environments, present a clear-eyed view of the ROI, and offer a path forward that aligns with the principles of high-velocity, cost-efficient, and scalable software development.
The Broken Promise of the Monolithic Staging Environment
The traditional, long-lived staging environment was born in a simpler, monolithic era. It was a single, stable pre-production replica where final integration testing could occur. However, when applied to a complex microservices ecosystem running on Kubernetes, this model fundamentally breaks down.
As Kelsey Hightower, a prominent voice in the cloud-native community, has often noted, the goal of modern platforms should be to enhance the developer experience, yet traditional staging frequently does the opposite.3 It becomes a source of friction, not empowerment.
The core issues are systemic:
- The Bottleneck Effect: When dozens of developers must queue for their turn to deploy and test on a single shared environment, parallel development ceases to exist. This queuing behavior directly contradicts the agile principles that microservices are meant to enable.
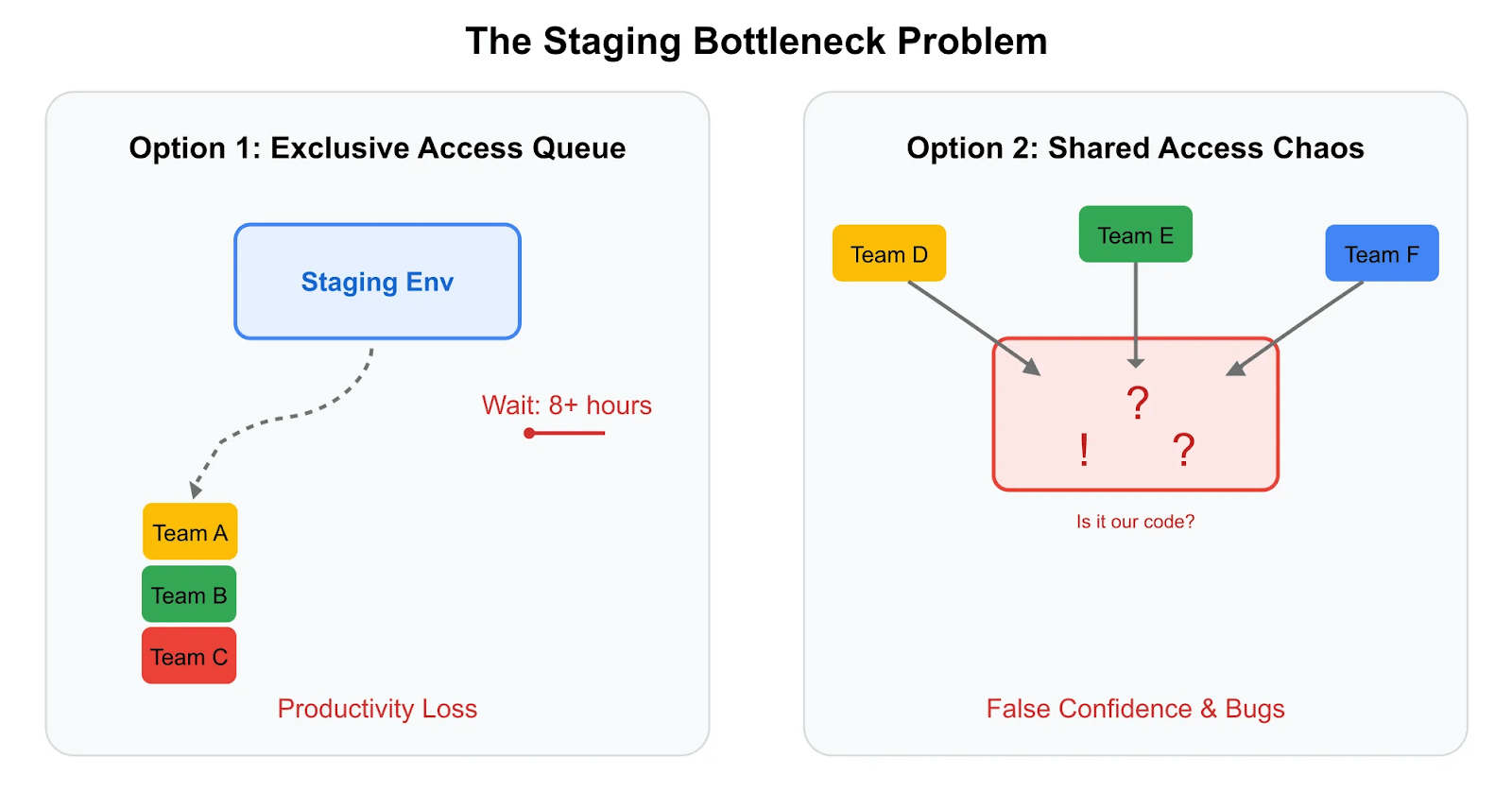
- Chronic Instability: A shared environment is only as stable as the least stable service deployed to it. A single buggy commit can destabilize the entire system, blocking every other team from making progress. This leads to what one engineering leader described as a “crowded nightclub: everyone wants in, capacity is limited, and fights break out regularly”.
- Configuration Drift: Long-lived environments are notoriously difficult to keep in perfect sync with production. Over time, manual changes, forgotten test data, and inconsistent updates cause the environment to “drift,” diminishing the value and reliability of the tests performed within it.
- Exorbitant Hidden Costs: Beyond the visible infrastructure spend, the true cost of staging is buried in lost engineering hours. Industry reports reveal that non-production environments can account for 27% of a company’s total cloud costs, with staging alone consuming up to 21% of ongoing maintenance efforts. When you factor in wasted developer time, which surveys show can be over 8 hours per week per developer due to technical inefficiencies, the financial impact becomes staggering.
The Rise of Ephemeral Environments: A Step in the Right Direction
In response to these limitations, the industry has shifted towards a more dynamic paradigm: ephemeral environments. An ephemeral environment is an on-demand, isolated, and temporary deployment created automatically for a specific, short-term purpose, such as testing a pull request.
Unlike their static predecessors, these environments are treated as disposable components of the development workflow. They are provisioned when a PR is opened and automatically destroyed upon merge or closure, ensuring a clean slate for every set of changes and conserving infrastructure resources. This approach aligns with the “shift-left” philosophy of catching issues earlier in the development lifecycle, when they are exponentially cheaper to fix.
The core attributes of a well-architected ephemeral environment system are:
- On-Demand & Temporary: Environments are created and destroyed automatically, aligning their lifecycle with the feature being developed.
- Production-Like: To be effective, a preview environment must mirror the production environment as closely as possible, using similar services, dependencies, and data schemas.
- Isolated: Each environment is self-contained, ensuring that tests for one PR cannot interfere with another, enabling true parallel development.
While the concept is powerful, the implementation strategy is where the paths diverge, with profound implications for cost, speed, and scalability.
The Great Divide: Two Models of Ephemeral Environments
Model 1: Full Environment Duplication (Infrastructure-Level Isolation)
The most conceptually straightforward approach is to duplicate the entire application stack for every pull request. This typically involves creating a new Kubernetes namespace and deploying all microservices and their dependencies into it. Tools like Okteto and Release are often associated with this philosophy of providing complete, replicated environments.
Strengths:
- Maximum Isolation: This model provides the highest possible degree of isolation. Each environment is a complete, self-contained replica, eliminating any chance of cross-contamination between tests.
- Simple Mental Model: The concept is easy for developers to grasp—every PR gets its own private copy of the application.
Weaknesses and Business Impact:
The simplicity of this model hides crippling inefficiencies that become apparent at scale.
- Prohibitive Infrastructure Costs: The financial burden of this approach is staggering. Let’s run some conservative “napkin math” for a 100-developer team with a 50-microservice architecture:
- Assuming each service requires 2 vCPUs, and environments are active for 8 hours per weekday, the annual compute cost alone can exceed $832,000.
- This calculation doesn’t even include the cost of replicated databases, message queues, and other stateful services. For a company like Brex, with over 1,000 microservices, their homegrown preview environments based on this model were nearly as expensive as their production environment, leading them to seek a more scalable solution.
- Slow Provisioning and Long Feedback Loops: Spinning up a full stack of 50+ services is not instantaneous. Wait times of 20-30 minutes are common, even after significant optimization. This reintroduces a slow feedback loop, delaying PR reviews and hindering the rapid, iterative cycle that is crucial for developer experience.
- Operational and Maintenance Nightmare: Your platform team becomes responsible for maintaining hundreds of replicas of your entire stack. Every configuration change, database migration, and security patch must be propagated across all environments. This creates an enormous maintenance burden that grows linearly with the number of developers, making configuration drift almost inevitable.
While full duplication appears to solve the problem of contention, it often backfires at scale, creating a distributed version of the same bottlenecks and adding an unsustainable financial and operational tax. As one developer on Reddit noted after attempting this approach, “It eventually worked, but took a very very long time… and also had a high operational overhead. It also got very expensive, very quickly”.
Model 2: Request-Level Isolation (Application-Layer Isolation)
A fundamentally different and more cloud-native approach is to achieve isolation at the application layer through intelligent request routing. This model, pioneered by tech giants like Uber and Lyft and commercialized by platforms like Signadot, is built on a shared infrastructure paradigm.
The architecture works as follows:
- Shared Baseline Environment: A single, long-lived “baseline” environment is maintained. This is typically an existing staging or QA Kubernetes cluster that is kept in sync with the main branch via CI/CD. It serves as the stable, high-fidelity foundation against which all changes are tested.
- Sandboxes and Service Forking: When a developer needs a test environment, they don’t clone the entire baseline. Instead, they create a lightweight, logical entity called a sandbox. The Sandbox definition specifies which one or two services are being modified. For these services, a “forked workload” is deployed—a new version running the code from the PR. All other unmodified services and dependencies in the baseline are shared, not copied.
- Dynamic Request Routing: This is the technological core that enables isolation on shared infrastructure. Test requests are tagged with a unique context, usually in an HTTP header (e.g., sd-routing-key=). A service mesh (like Istio or Linkerd) or a lightweight sidecar proxy intercepts traffic and inspects this header. If a routing key is present, the request is dynamically routed to the forked service in the corresponding Sandbox. If no key is present, it goes to the stable baseline service. This routing context is propagated throughout the entire downstream call chain, creating a virtual “slice” of the application for that specific test.
Strengths and Business Impact:
This innovative architecture yields a set of powerful benefits that directly address the primary pain points of other models.
- Drastic Cost Reduction: Since only the changed services are deployed, the resource overhead per environment is minimal. This can lead to infrastructure cost reductions of 90% or more compared to full duplication. For the same 100-developer team, the annual cost drops from over $800,000 to around $68,000. Brex, a Signadot customer, reported saving $4 million annually on infrastructure after making this switch.
- Blazing-Fast Environment Creation: Sandboxes spin up in seconds because there’s no need to wait for dozens of services to be provisioned. This provides a near-instantaneous feedback loop, allowing developers to preview changes almost as soon as they push code. DoorDash reported that this approach accelerated their testing by 10x, cutting deployment time significantly.
- High-Fidelity Testing: Developers test their changes against the actual shared dependencies—the same databases, message queues, and third-party APIs that the baseline environment uses. This dramatically increases the likelihood of catching subtle, real-world integration issues that are often missed when testing against fresh, empty copies of these dependencies.
- Exceptional Scalability: The model scales effortlessly, supporting hundreds of concurrent Sandboxes on a single cluster without performance degradation or resource exhaustion. This is a critical capability for large, high-velocity engineering organizations.
The ROI of Intelligence: A Business Case for Request-Level Isolation
For engineering leaders, the decision to invest in a testing platform must be justified by a clear return on investment. The business case for request-level isolation is compelling, with measurable improvements across cost, velocity, and quality.
Quantifying the Gains with DORA Metrics
The DORA (DevOps Research and Assessment) metrics are the industry standard for measuring software delivery performance. An effective testing environment strategy should directly and positively impact these key indicators.
- Lead Time for Changes: This metric, which measures the time from code commit to production deployment, is dramatically reduced. By providing feedback in seconds instead of hours, request-level isolation slashes the “code-test-debug” cycle time. Teams like DoorDash have seen lead times for testing drop from 30 minutes to under 60 seconds.
- Deployment Frequency: By removing the staging bottleneck, teams can merge and deploy smaller batches of code more frequently, a key characteristic of elite-performing organizations.
- Change Failure Rate: Shifting high-fidelity integration testing left into the PR phase means more bugs are caught before code is merged. This leads to a cleaner main branch and fewer hotfixes or rollbacks after deployment. Earnest, another Signadot customer, boosted their release reliability by catching bugs earlier in the process.
- Mean Time to Recovery (MTTR): While primarily a production metric, faster, more reliable pre-production testing reduces the number of incidents that require recovery in the first place, contributing to overall system stability.24
The Unquantifiable ROI: Developer Experience (DevEx)
Beyond hard metrics, the impact as stated in this article is profound. As articulated in a recent ACM Queue article, the three pillars of a great DevEx are short feedback loops, low cognitive load, and enabling a “flow state”. Traditional testing models actively work against all three.
In contrast, a seamless, fast, and reliable testing environment is a strategic asset for attracting and retaining top engineering talent. As one Software Engineering Manager at Brex, Connor Braa, put it, “On the margin, with the Signadot approach, 99.8% of the isolated environment’s infrastructure costs look wasteful. That percentage looks like an exaggeration, but it’s really not”. This level of efficiency directly translates to a better daily experience for developers, allowing them to focus on creative problem-solving instead of fighting with broken infrastructure.
Handling the Hard Parts: Stateful Services and Asynchronous Flows
A common and valid question about the shared infrastructure model is how it handles stateful services and asynchronous workflows. A mature request-level isolation platform must provide robust solutions for these complex scenarios.
- Databases and Schema Changes: Testing destructive database schema changes requires careful isolation. The solution is to use resources, an extensible framework that allows a Sandbox to spin up its own ephemeral, isolated database instance or schema for the duration of a test. This provides the necessary data isolation for stateful changes without the overhead of cloning the main database for every PR. You can see a detailed walkthrough in our tutorial on how to test database schema changes.
- Message Queues (Kafka, RabbitMQ, etc.): Testing event-driven architectures requires a more sophisticated pattern to isolate messages. The solution involves propagating the routing context within the message headers or metadata. On the other side, consumer services within a Sandbox are configured for “selective consumption”—they are programmed to only process messages that contain their specific routing key. This ensures that test messages are isolated from the main message stream and are only consumed by the correct test instance. This pattern works across all major message brokers, and you can explore a hands-on example in our tutorial on testing asynchronous Kafka flows.
The evolution of testing environments for microservices reflects the maturation of the cloud-native ecosystem. We have moved from the brittle, monolithic staging environments of the past to a new era of dynamic, on-demand testing.
However, as we’ve seen, not all ephemeral environments are created equal. The choice between full environment duplication and request-level isolation is a strategic one that will define your organization’s ability to scale its development practices efficiently and economically.
While full duplication offers a simple mental model, it is a solution that collapses under its own weight and cost at scale. It is a tactical fix that fails to address the fundamental architectural challenges of testing distributed systems.
Request-level isolation represents a paradigm shift. By moving isolation from the infrastructure layer to the application layer, it decouples the cost and complexity of testing from the overall size of the application. The cost of a test environment is no longer proportional to the total number of microservices (N), but to the number of changed microservices in a given pull request (M), where M is almost always a small fraction of N.
This economic and logistical reality makes the request-level isolation model—as implemented by Signadot—uniquely capable of supporting true, independent, high-velocity microservice development for large and growing engineering organizations. It is the enabling technology for teams seeking to test every change thoroughly, accelerate their release cycles, and deliver higher-quality software, all without breaking their infrastructure budget.

