Many teams assume microservices testing will scale smoothly as they grow — but the opposite happens. This article breaks down why testing complexity grows exponentially with more services, and how smart, isolated environments can help break the bottleneck before it breaks your team.
Image by Steven Johnson from Unsplash.
The logical assumption that testing will get easier if your engineering team scales along with your microservices growth is completely wrong.
I was chatting with a VP of engineering last week who made an observation that stuck with me: “When we had five microservices, testing was actually easier than our old monolith. At 50 services, it’s become our biggest bottleneck.”
This isn’t uncommon. Most teams experience a honeymoon period with microservices where testing feels manageable, even elegant. Then something shifts. What was once a competitive advantage becomes a drag on velocity. The question is: Why does microservices testing difficulty seem to grow exponentially, rather than linearly?
In the beginning, microservices testing feels like a breath of fresh air. You’ve got clean service boundaries and focused test suites, and each team can move independently. Testing a payment service? Spin up the service, mock the user service and you’re done. Simple.
This early success creates a reasonable assumption that testing complexity will scale proportionally with the number of services and developers. After all, if each service can be tested in isolation and you’re growing your engineering team alongside your services, why wouldn’t the testing effort scale linearly?
It’s a logical assumption. And it’s completely wrong.
The reality is that testing complexity in microservices grows exponentially due to several compounding factors that aren’t obvious when you’re starting out.
With five services, you might have eight or 10 integration points to test. But integration points don’t scale linearly — they scale based on the interconnectedness of your system.
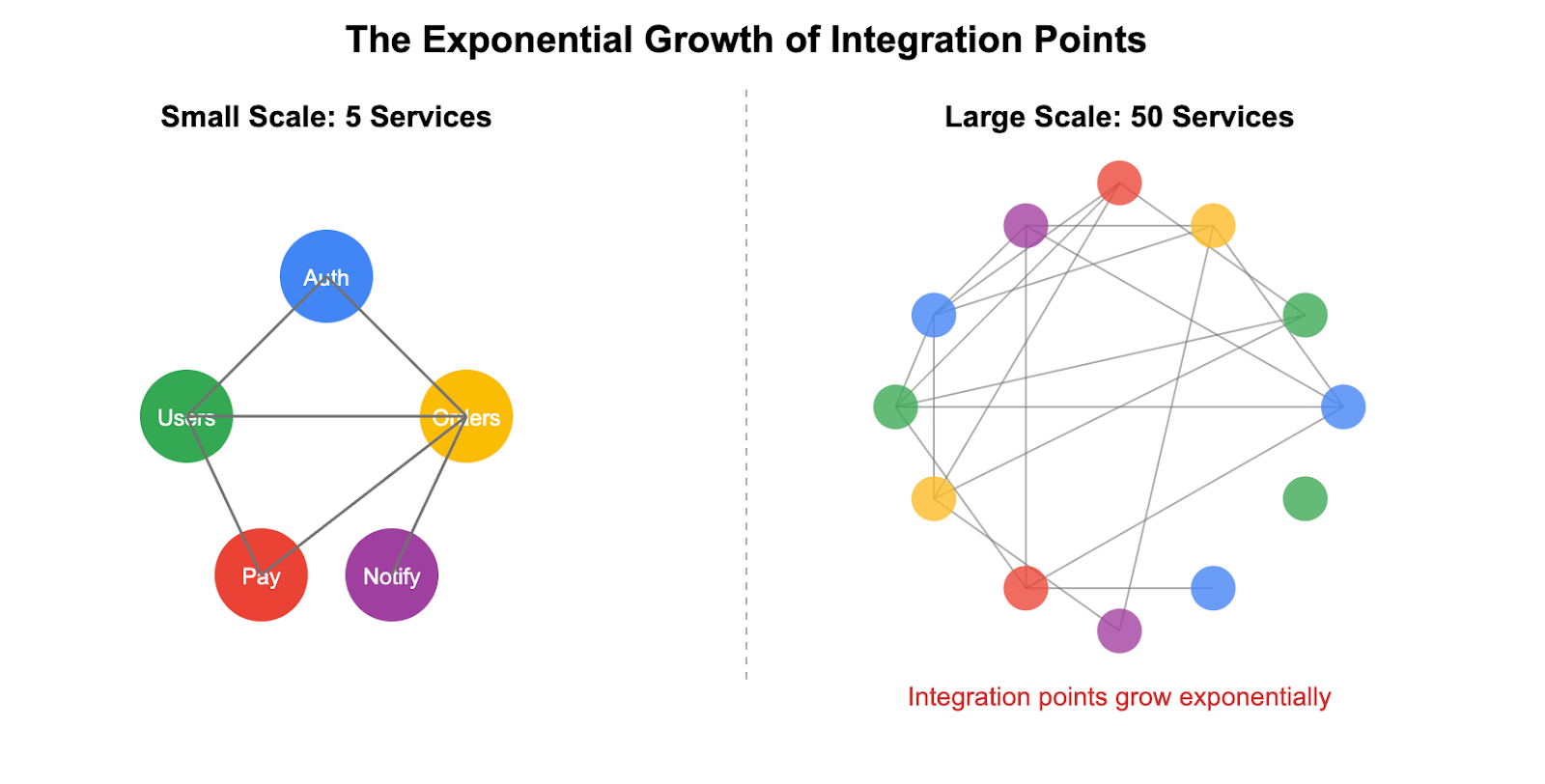
Source: Signadot.
Think about it: Each service doesn’t just call one other service. A typical microservice might integrate with four to six other services — authentication, logging, data storage, notification services, plus two or three business logic services. As your architecture grows, services become more interconnected, not less. That order service doesn’t just talk to inventory; it also hits payment processing, user management, shipping, analytics and audit logging.
The result? Integration points grow much faster than the number of services, creating a web of dependencies that must be validated.
Each new service doesn’t just add its own test requirements. It potentially interacts with multiple existing services, creating a web of dependencies that must be validated. What started as simple point-to-point testing becomes a complex and sprawling validation challenge.
Mocking strategies that work beautifully at a small scale become maintenance disasters at a large scale. One API change can require updating dozens of mocks across different codebases, owned by different teams.
A platform engineering director recently told me: “We calculated that our teams spend 40% of their testing time just maintaining mocks.”
With five services, maintaining three to four test environments per team feels reasonable. Scale to 50 services across 15 teams, and suddenly you need 45-60 environments. The infrastructure costs and operational complexity become staggering.
One of our customers was spending $2 million annually just on pre-production environments before it rethought its approach. The ops team was spending more time maintaining test infrastructure than building new capabilities.
This is precisely the million-dollar problem of slow microservices testing that organizations face as they scale beyond a handful of services.
Perhaps the most painful scaling challenge is what happens to shared staging environments. With a few services, staging works reasonably well. Multiple teams can coordinate deployments, and when something breaks, the culprit is usually obvious.
But as you add services and teams, staging becomes either a traffic jam or a free-for-all — and both are disastrous.
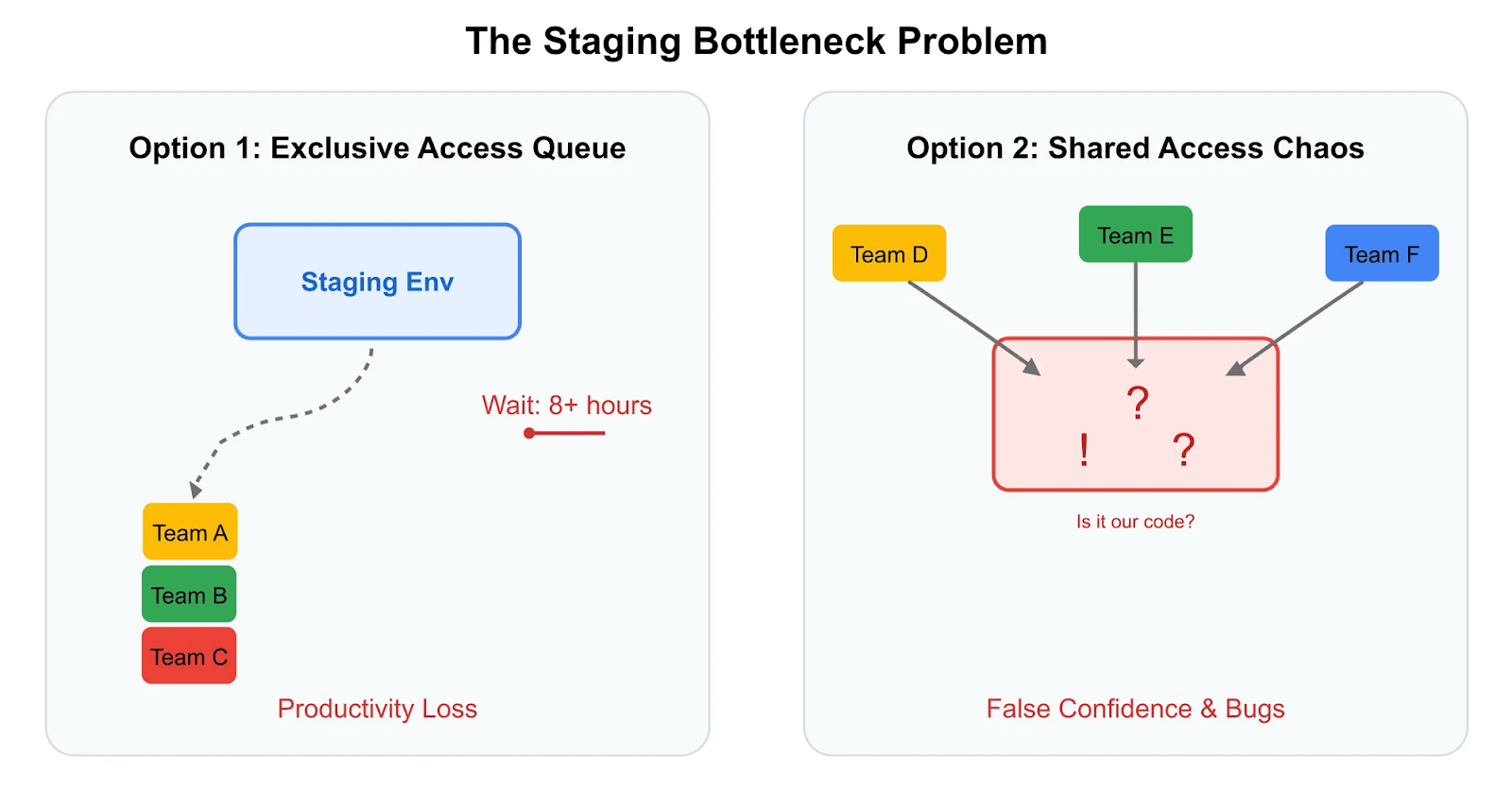
Source: Signadot.
Some organizations implement strict scheduling where teams get exclusive staging access. I’ve seen teams wait eight or more hours for their turn, with elaborate coordination systems — Slackbots, deployment calendars and other mechanisms — to manage the queue.
The math here is brutal. If you have 20 teams each needing staging access twice per week, and each testing session takes two hours, you need 80 hours of staging time weekly. But you only have 40 hours (one environment, Monday through Friday). At an average fully loaded engineering cost of $150 per hour, those wait times translate to thousands of dollars in lost productivity weekly. One organization we work with calculated it was burning $400,000 annually just on engineers waiting for staging access.
More commonly, teams share staging concurrently without coordination. No waiting, but now multiple teams are deploying and testing simultaneously. Test failures become meaningless — is it your code or someone else’s deployment that broke the flow?
This creates a perverse outcome: Developers lose trust in test results and start ignoring failures, assuming they’re environment-related. Teams push code to production despite failing tests, leading to production incidents. The very environment meant to catch bugs before production becomes a source of false confidence.
This is exactly why staging doesn’t scale for microservice testing — the fundamental assumptions break down as teams and services multiply.
As testing becomes more painful, teams begin developing workarounds that make the underlying problems worse:
The teams that successfully scale microservices testing have figured out how to break this exponential curve. They’ve moved away from trying to duplicate production environments for testing and are instead focused on creating isolated slices of their production-like environment.
Instead of spinning up 50 services for every test scenario, they spin up only the two or three services being modified and route test traffic to production-like versions of everything else. This smart ephemeral environment approach caps the complexity growth while maintaining high-fidelity testing.
Here’s how this breaks each of the exponential scaling problems:
One customer explained it perfectly: “We stopped trying to recreate the entire world for every test. Instead, we create a small bubble of change and test how it interacts with the real world.”
Microservices testing doesn’t have to become exponentially complex as you scale. The key is recognizing early that traditional testing approaches don’t scale beyond 10-15 services and adopting testing that grows linearly with your architecture.
At Signadot, we’ve built a platform that enables sandbox environments for exactly this problem — allowing teams to test individual changes against production-like dependencies without the exponential complexity. If you’re hitting the testing wall, try it for free and see how linear scaling changes everything.
Get the latest updates from Signadot

