An implementation for Kafka message-level isolation solution by combining the use of Sandboxes with our recently released Routes API
So far, we have extensively shown how to use Signadot to perform different kinds of testing, including end-to-end, integration, API testing, and even exploratory testing during the development phase by running local sandboxes. But most of those cases were mainly focused on synchronous microservice architectures, in which, the communication between services is performed synchronously via RPC calls, such as REST or gRPC APIs. The reason behind this is that asynchronous architectures present a different set of challenges, a much more open-ended field, which makes implementing a testing solution something more complex to achieve.
As a testing platform, we heavily rely on context propagation and routing. The first to propagate through all the services the required information to perform routing, and the second to direct the testing traffic to the right destination. In the case of synchronous architectures, context propagation is a given, a well-known concept supported by multiple libraries across multiple languages, even standardized by the OpenTelemetry project. On the other hand, there are several service mesh solutions, such as Istio or Linkerd, that perfectly fit our routing needs. But when it comes to asynchronous architectures, context propagation is not so well defined, and service mesh solutions simply do not apply, or at least, not at the moment (they operate at the request or connection level, but not at a message level as we may need).
In a previous article, we presented different approaches to perform testing on Kafka-based asynchronous workloads:
1. Isolate Kafka Cluster, in which a new Kafka cluster has to be provisioned per Sandbox (using Signadot Resources), and all producers and consumers have to be forked, pointing them to the sandboxed Kafka cluster.
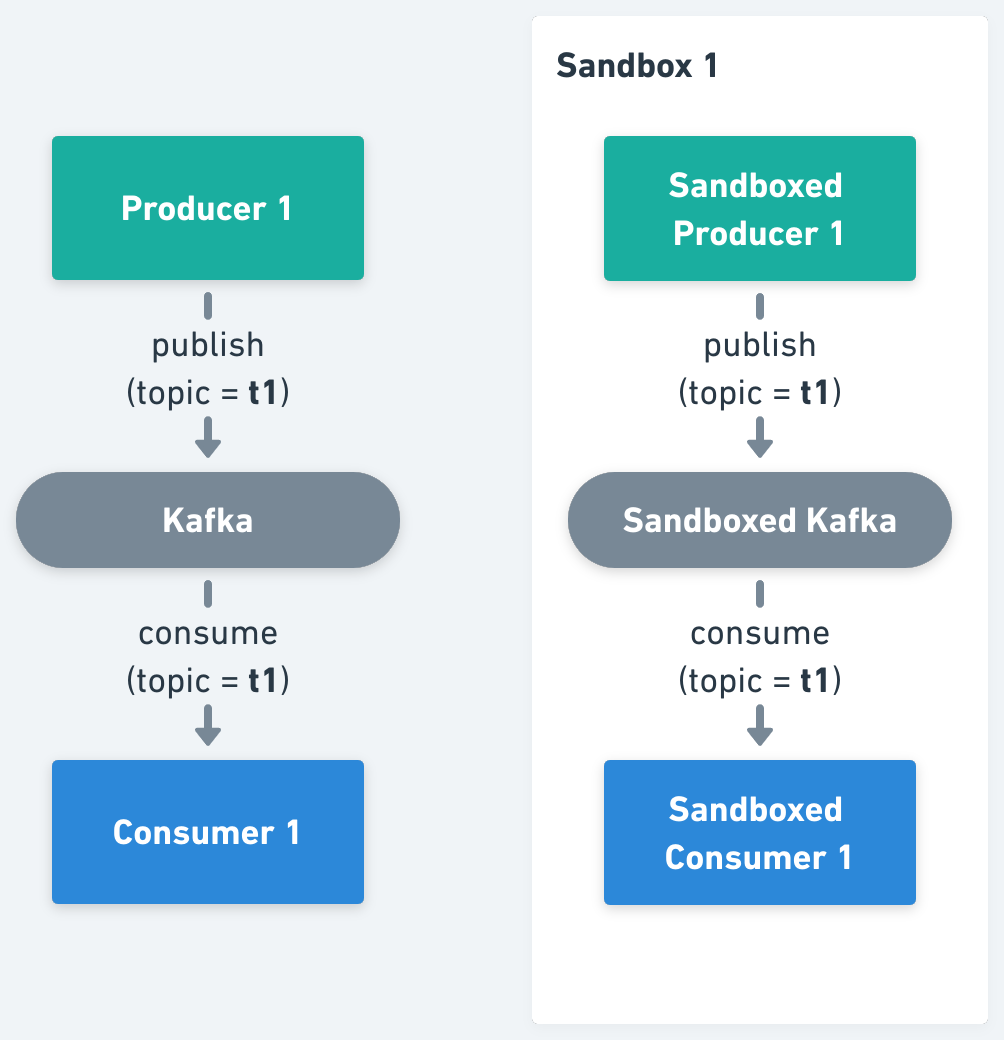
2. Isolate Kafka Topics, where all producers and consumers should be forked, pointing them to the per Sandbox topic.
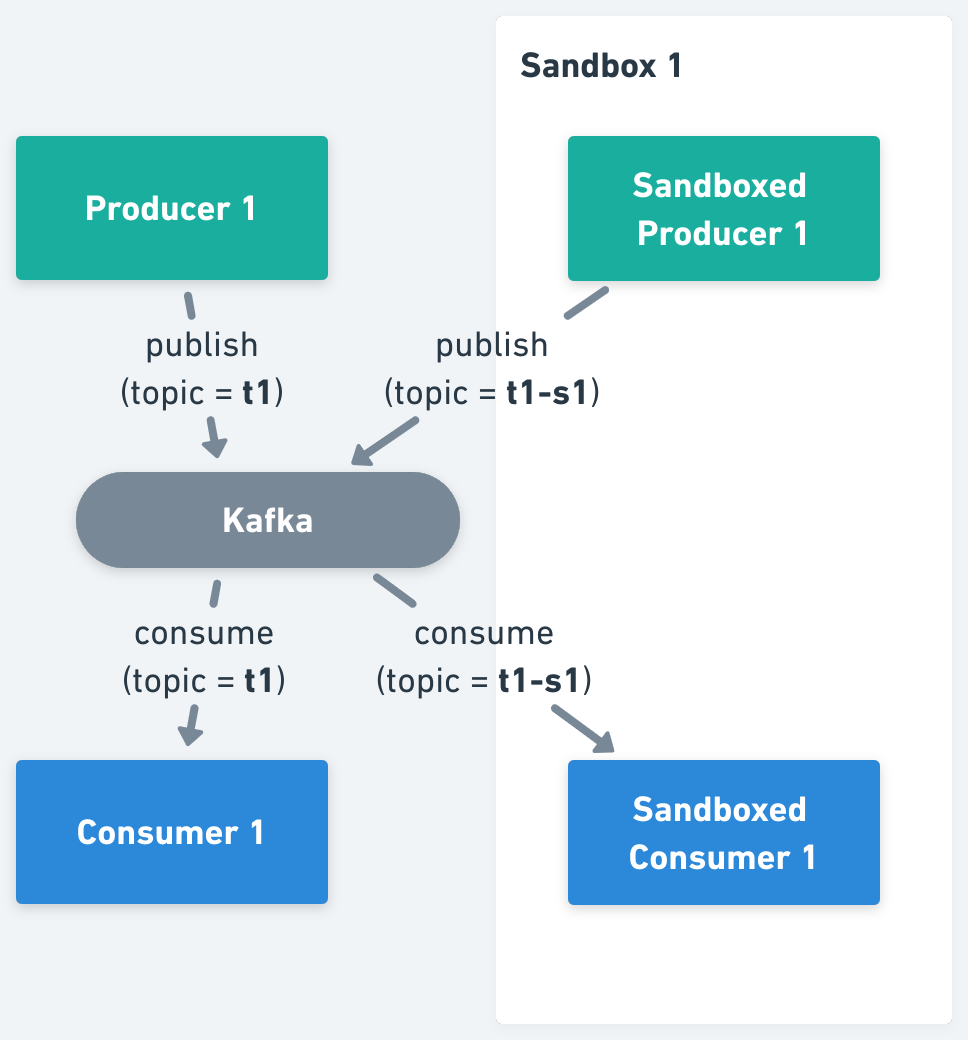
3. Isolate Kafka Messages, a theoretical solution, intending to mimic the same experience as using Sandboxes in synchronous architectures, in which depending on the context of a received message, and the identity of a consumer, the message is processed or not.
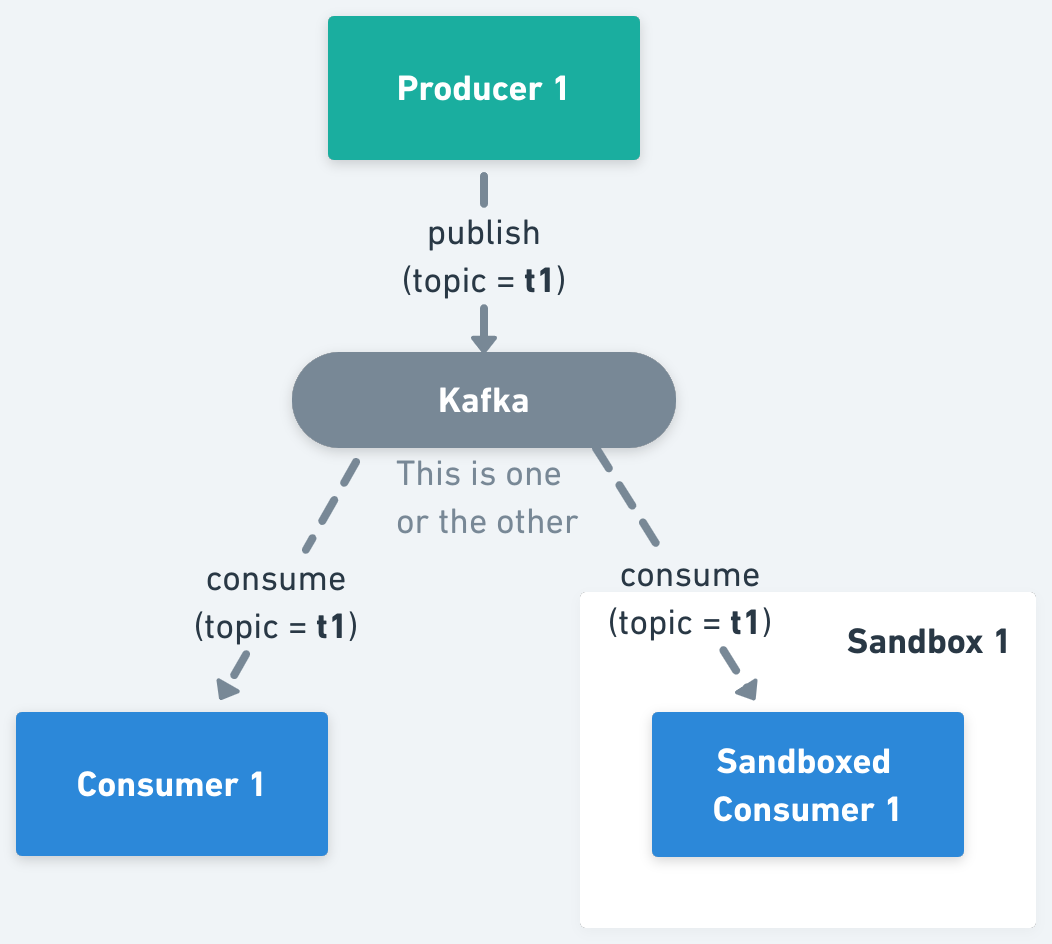
As part of said article, we also presented the pros and cons of each of those approaches, concluding that message-level isolation was the optimal solution for most of the cases.
In the current article, we will present an actual implementation for the message-level isolation solution, by combining the use of Sandboxes with our recently released Routes API.
The idea behind this solution is to perform a selective consumption of messages on the consumer workloads, ensuring that each message is consumed by one and only one version of the consumers. For example, if an application has a consumer C1 (we will refer to it as the baseline version of the workload) and we fork it within a Sandbox S1 creating C1' (also known as a sandboxed version of the workload), both C1 and C1' will subscribe to the same topic, but only one of them will process the message depending on its context.
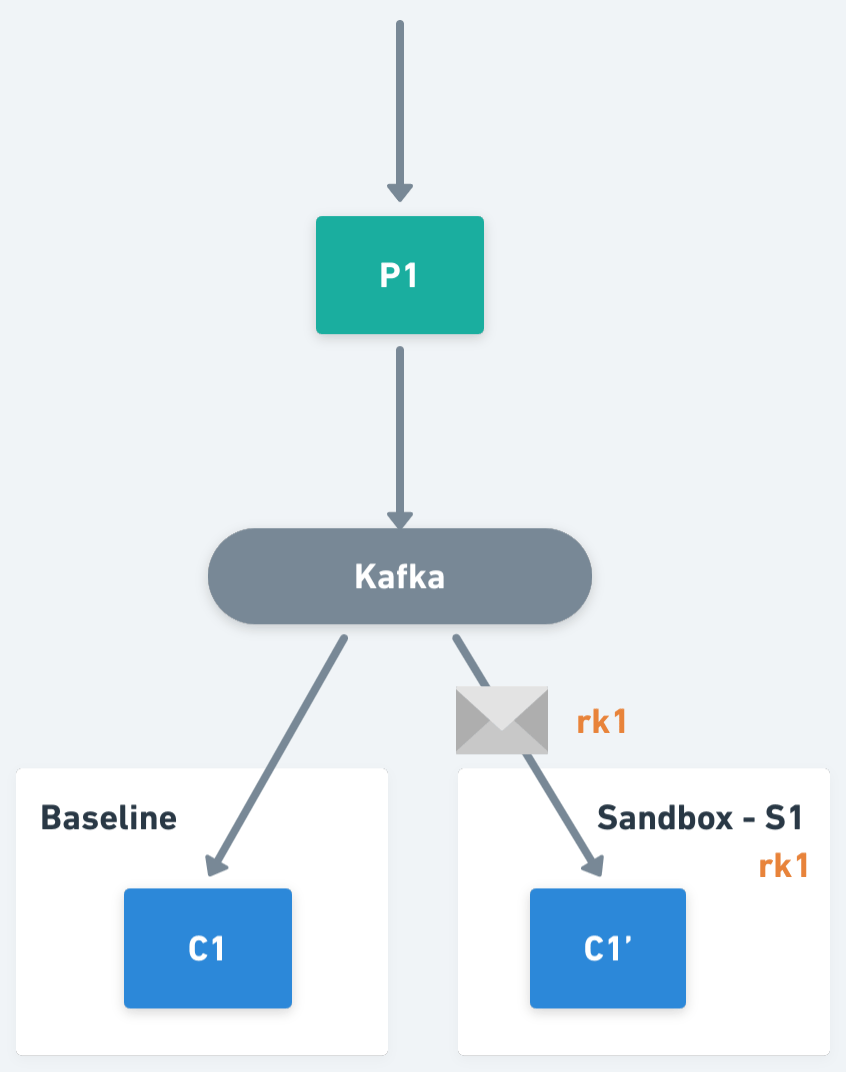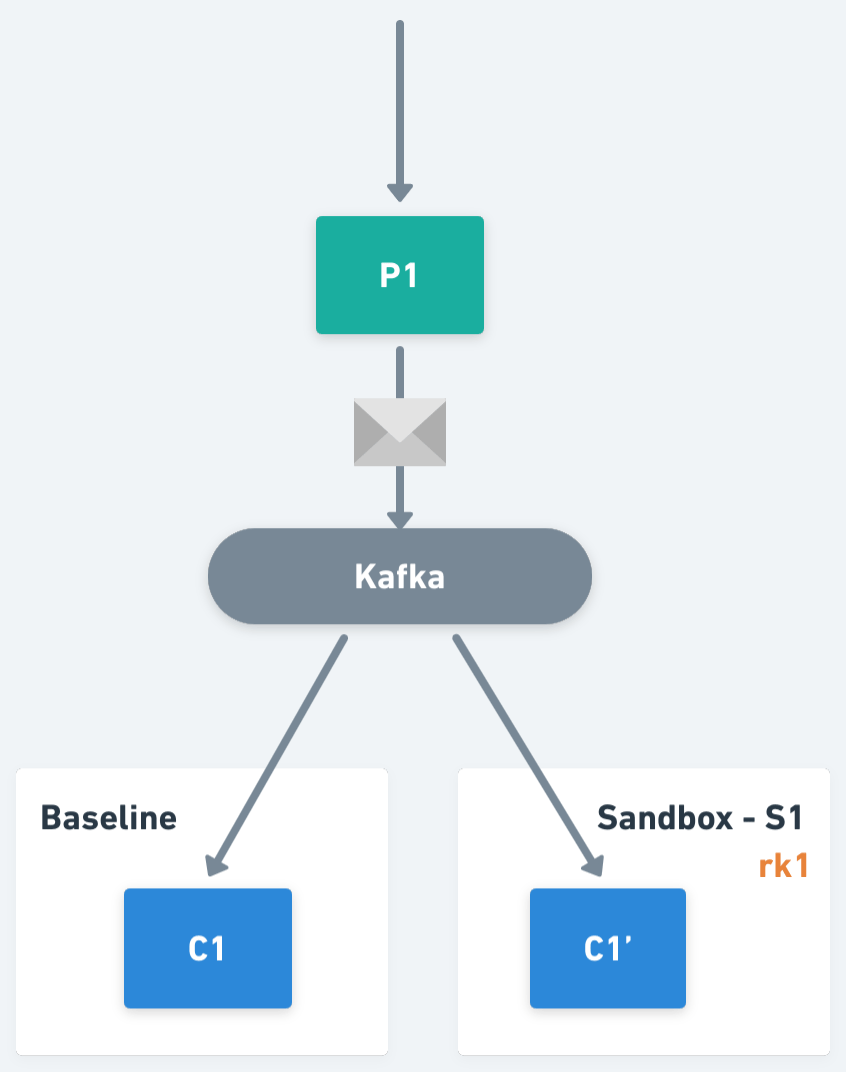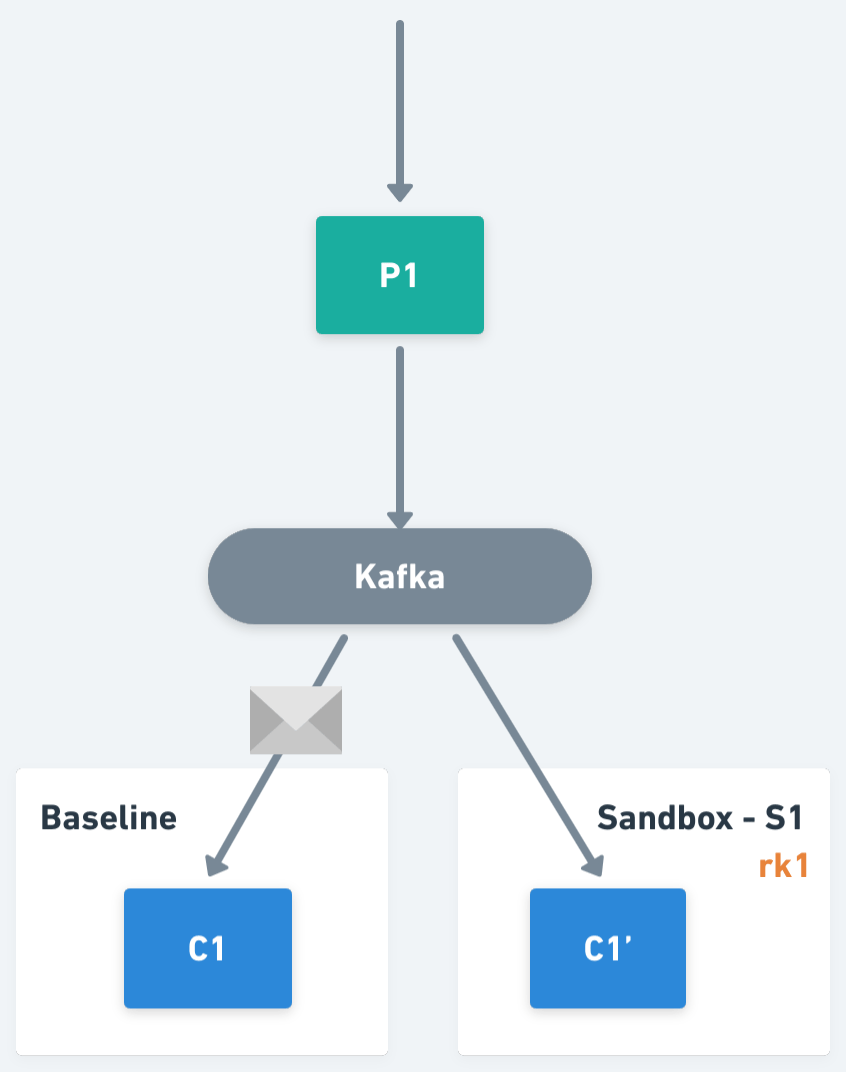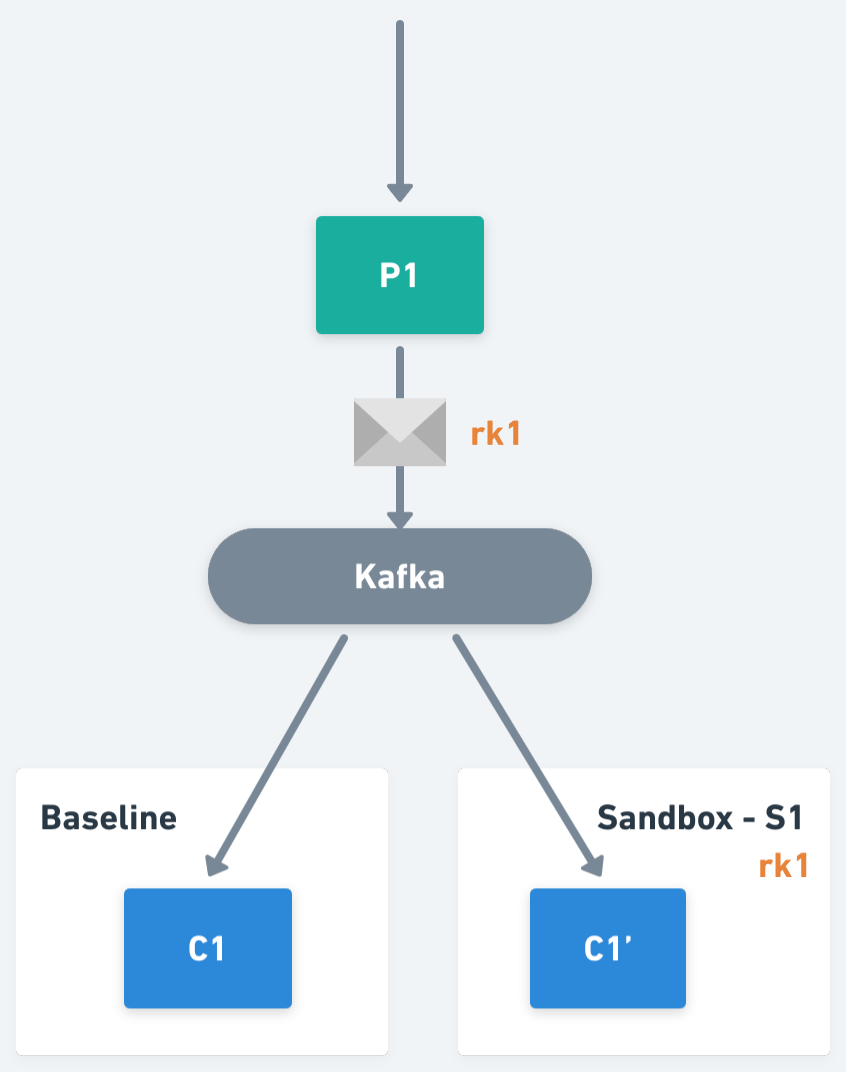
At this point, an important question is what is the data and the logic required to execute said selective consumption in the consumer workloads. Let’s go deeper about this.
One of the key primitives within the Signadot Operator is the routing key, an opaque value assigned to each Sandbox and Route Group, used to perform request routing within the system. In the case of asynchronous applications, we will also propagate routing keys as part of the message headers, and we will use them to determine the workload version responsible for the processing of a message.
Now, If we think from the perspective of a sandboxed workload, it will be responsible for responding to multiple routing keys. In particular, for the one assigned to the Sandbox who created it, plus the routing keys assigned to each of the Route Groups containing that Sandbox. So, continuing with the previous example, we have Sandbox S1, which has been assigned routing key rk1, and there is Route Group RG1 that has routing key rk2 assigned, then the workload C1' should process traffic including routing keys rk1 and rk2.
On the other hand, if we think from the perspective of a baseline workload, it should only process the traffic without routing keys, or with routing keys not matching the keys assigned to any of its sandboxed workloads. Extending the example, imagine that now we also have Sandbox S2, with routing key rk3 that forks consumer C1, generating C1". C1' will be responsible for routing keys rk1 and rk2. C1" will be responsible for routing key rk3. And C1 (the baseline) will process all the other traffic (i.e. traffic not matching with routing keys rk1, rk2 or rk3).
This means, the logic and the data required for each of these cases, are similar but not the same. In the case of sandboxed workloads they will require:
And the consumption logic will be: if the message routing key is included in the set from 2., then process the message, otherwise ignore it.
In the case of baseline workloads, they will require:
The logic being: if the message routing key is included in set from 2., then ignore the message (it will be processed by the corresponding sandboxed workload), otherwise process it.
An important detail to implement this logic in Kafka is to make sure each of the different versions of a consumer workload belongs to a different Kafka consumer group. That way all workloads will have access to all messages in the topic. A simple solution to this is, in the case of sandboxed workloads, appending the sandbox name to the consumer group (which is available as an environment variable). This will prove unique given within a Sandbox there can only be one sandboxed version of a given baseline.
In Signadot Operator v0.15.0, we released the Routes API, a set of endpoints (gRPC and REST), implemented by the Route Server that exposes Sandbox routing information within the Kubernetes cluster. In the case of the gRPC, the routing information can be accessed by pulling or by using streams (which works in an almost real-time manner). This is the API we will use to collect the required information to perform the selective consumption logic both from baseline and sandboxed workloads (in particular, point 2. from above).
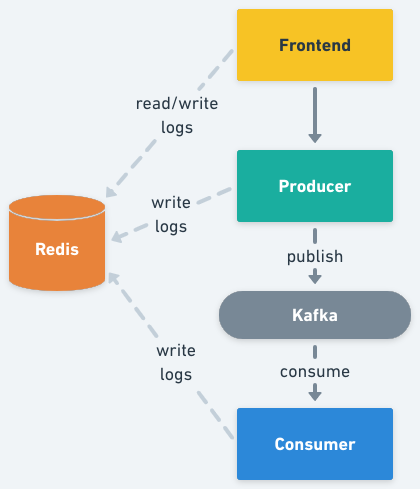
To demonstrate how all of this works together, we developed a basic Node.js application. You can find the source code in here.
The application is formed by three microservices, the frontend, the producer, and the consumer, one Kafka cluster, and one Redis server. The frontend exposes an HTTP server from where static content can be accessed (HTML, images), and a minimal REST API with two methods, one for publishing a message, and another for getting log entries. The producer exposes a REST API with a single method that is called from the frontend every time a user submits a new message. Upon receiving a request it publishes the message in Kafka with the provided information (by default in the topic kafka-demo). The consumer performs the selective consumption of messages from Kafka, implementing the logic described in the previous section, using the REST version of the Routes API to pull the required routing keys. The three services from above implement context propagation via OpenTelemetry, and upon receiving requests or consuming messages from Kafka, they log those events in the Redis server. Finally, the frontend reads those logs and displays them on the UI (the browser will pull the frontend API every two seconds).
To run the demo application, first make sure you have the Signadot Operator ≥ v0.15.0 installed on your cluster. Next, create the kafka-demo namespace and install the provided manifests in the k8s directory (that will install a minimal Kafka cluster, a Redis server, the frontend, the producer, and the consumer):
kubectl create ns kafka-demo kubectl -n kafka-demo apply -f k8s/pieces
Wait until all the installed workloads are ready. You can check the status with the following command:
kubectl -n kafka-demo get statefulset,deployment
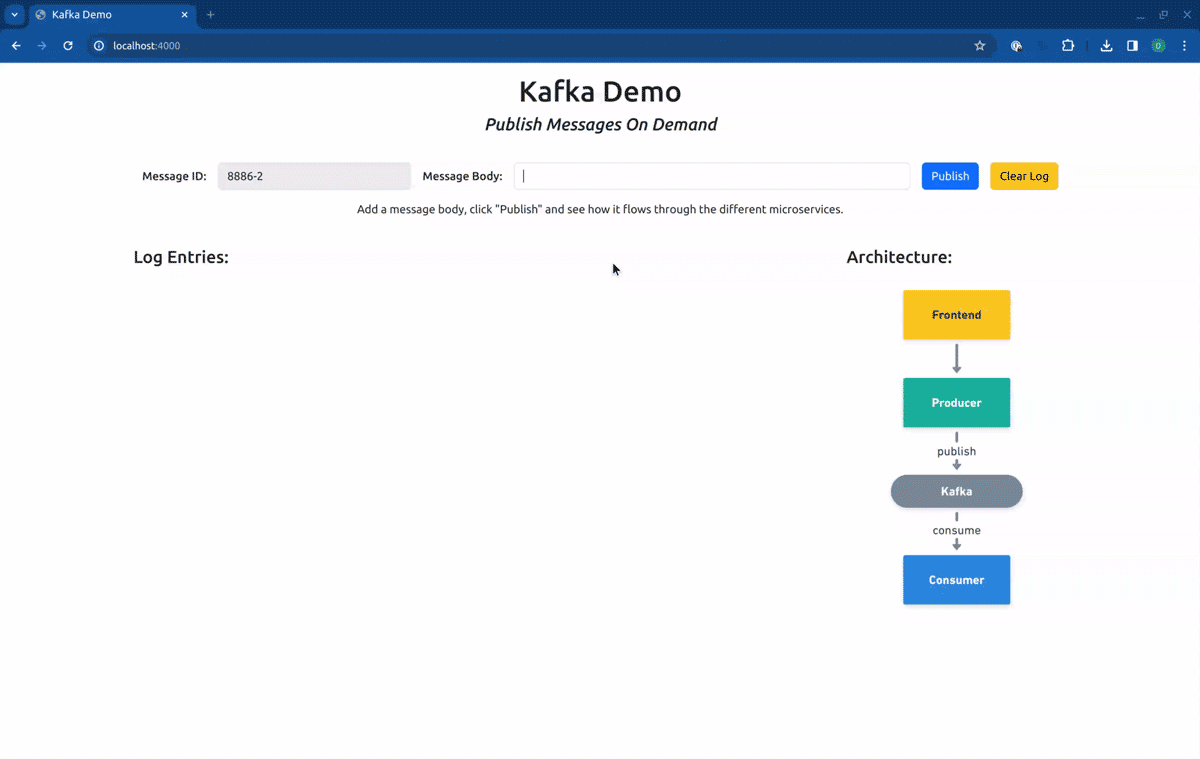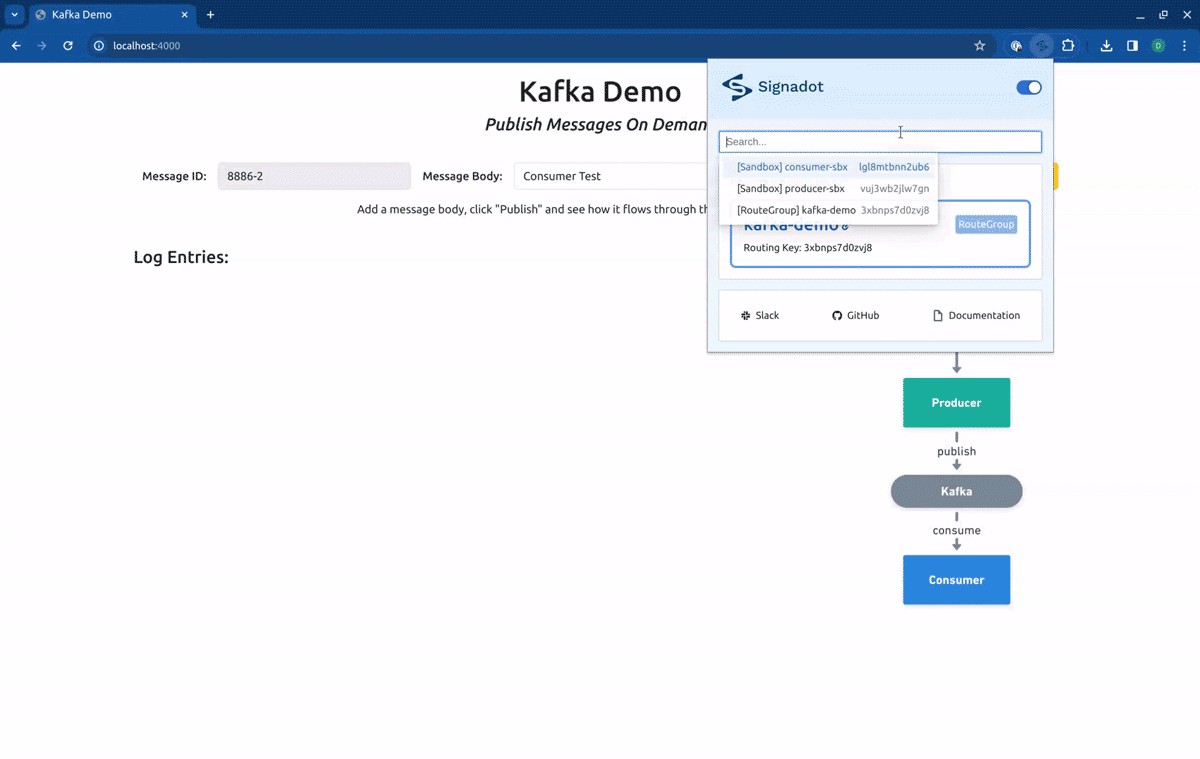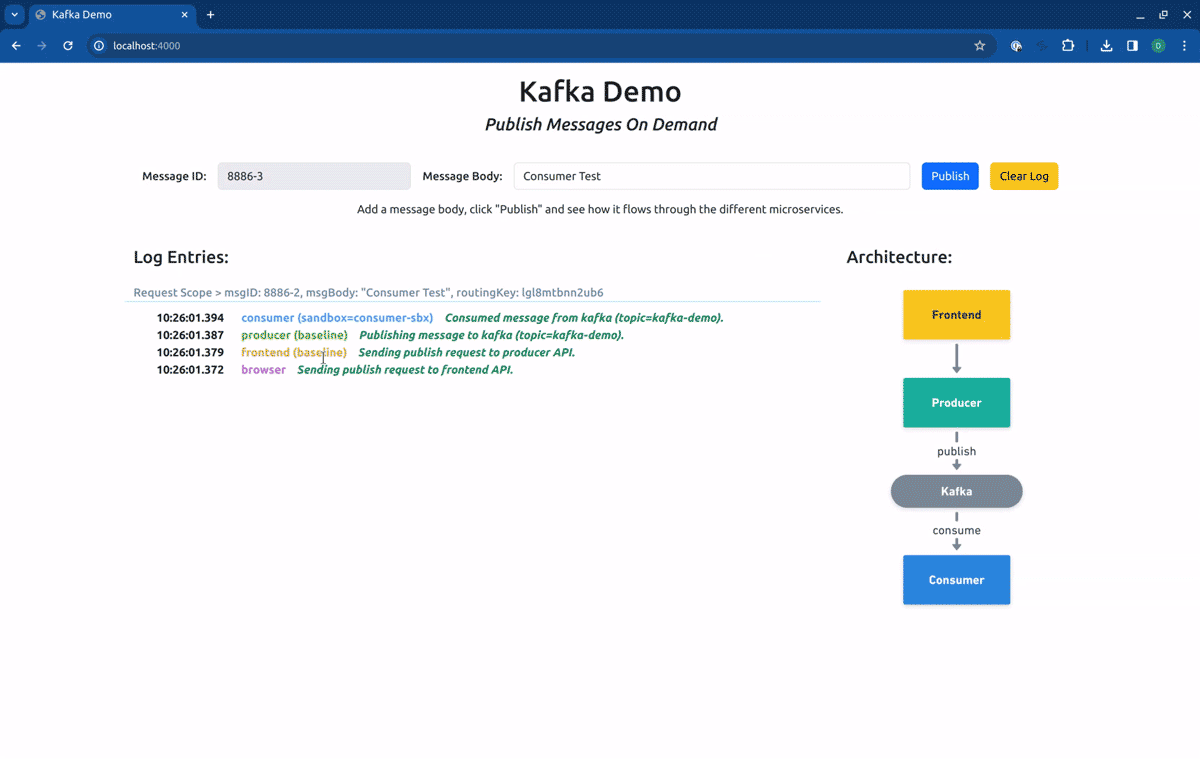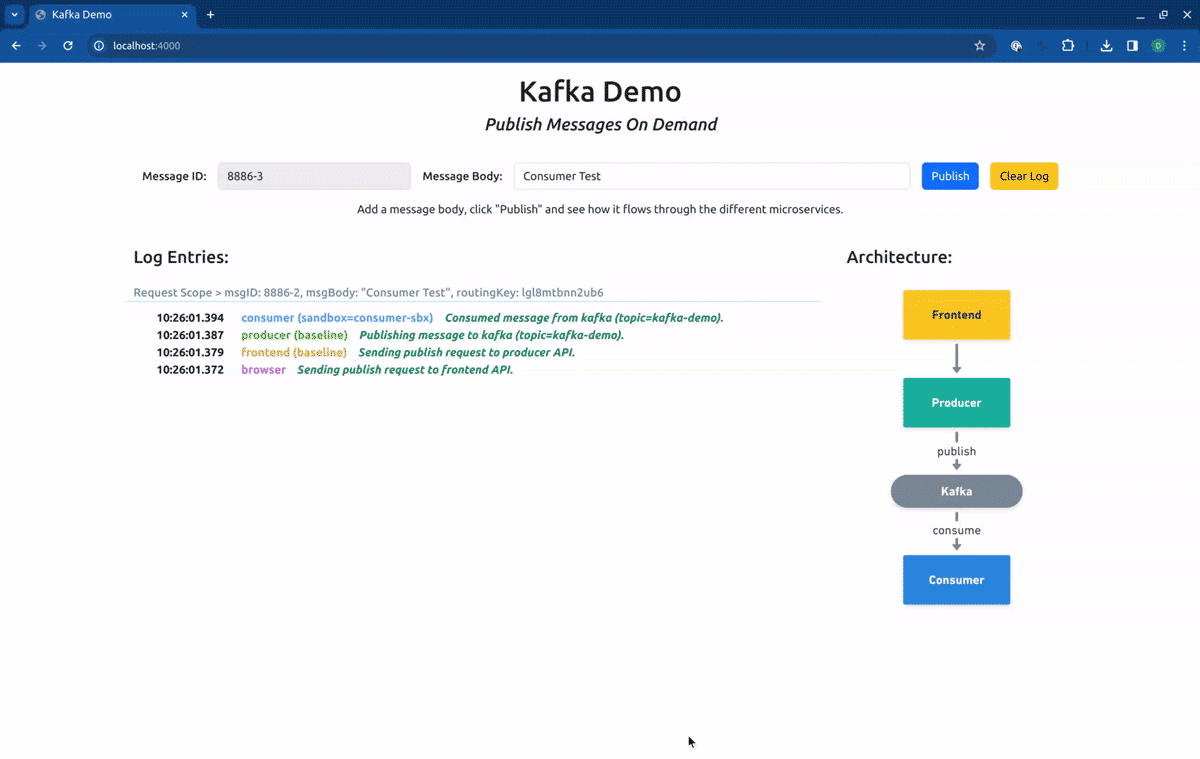
Let’s now create some sandboxes and route groups. We’ll start creating a Sandbox named consumer-sbx where we fork the consumer:
As you may notice, in the Sandbox specification we are not introducing any customization, which is certainly untypical, but it is good enough for the purposes of this demo. Similarly, we will create another Sandbox named producer-sbx where we just fork the producer:
Finally, we will create a Route Group named kafka-demo containing the two above sandboxes (note that the specified labels will match them):
We provide these examples as part of the application, so you can install them by running the following commands (replace [CLUSTER_NAME] with your corresponding cluster name):
Once ready, you can test using the generated preview URLs (included in the output from the above commands), and/or by accessing the Signadot Dashboard.
In this article, we will use a different method. Instead of using the preview URLs, we will use the Signadot Browser Extension to set the desired routing context for our requests. This will allow us to get better feedback from the application. To access the frontend service locally, we will execute a port-forward, by running:
kubectl port-forward service/frontend -n kafka-demo 4000:4000
Now the frontend will be available at http://localhost:4000/. Let’s see how it looks when we hit the baseline version of the services:
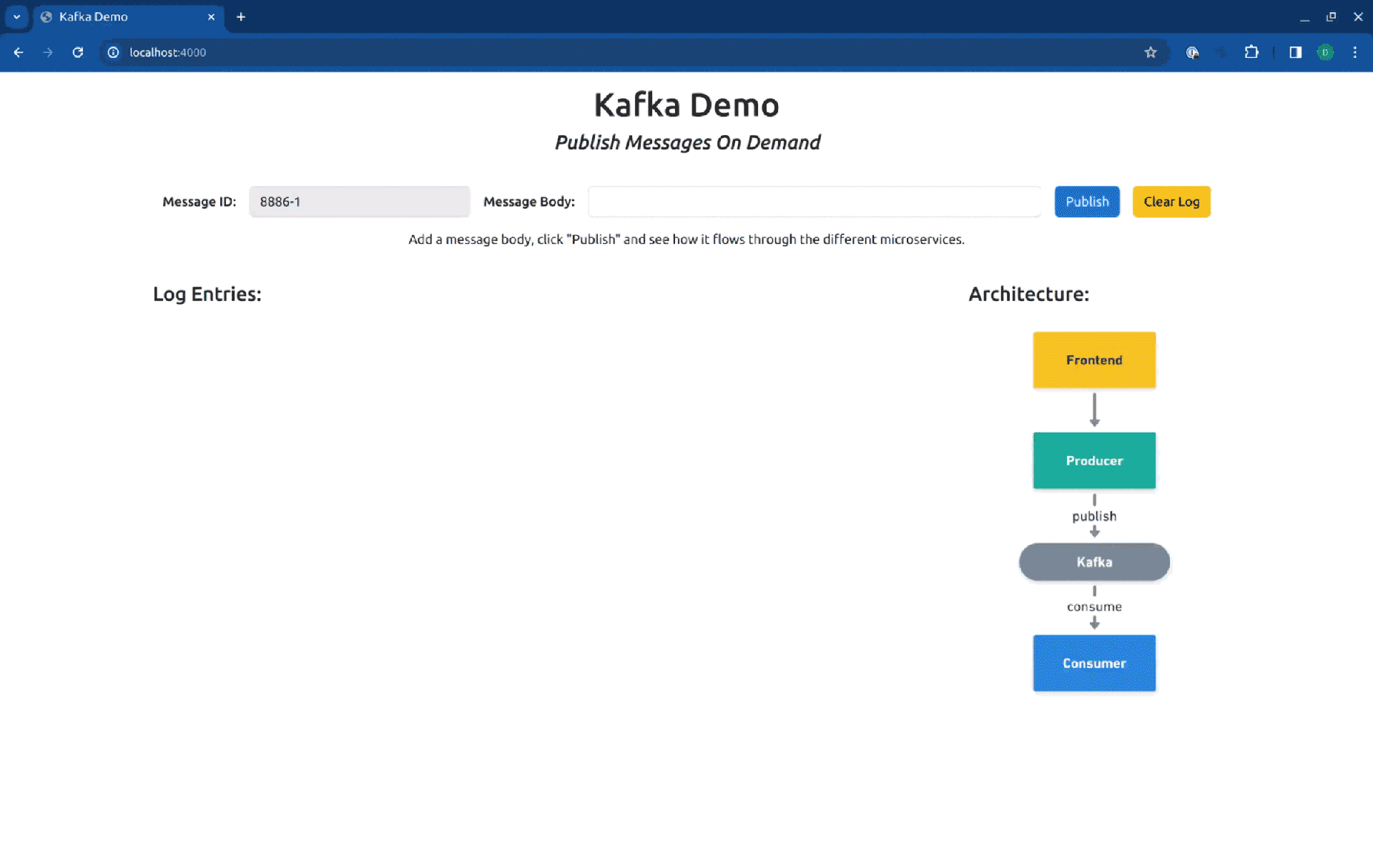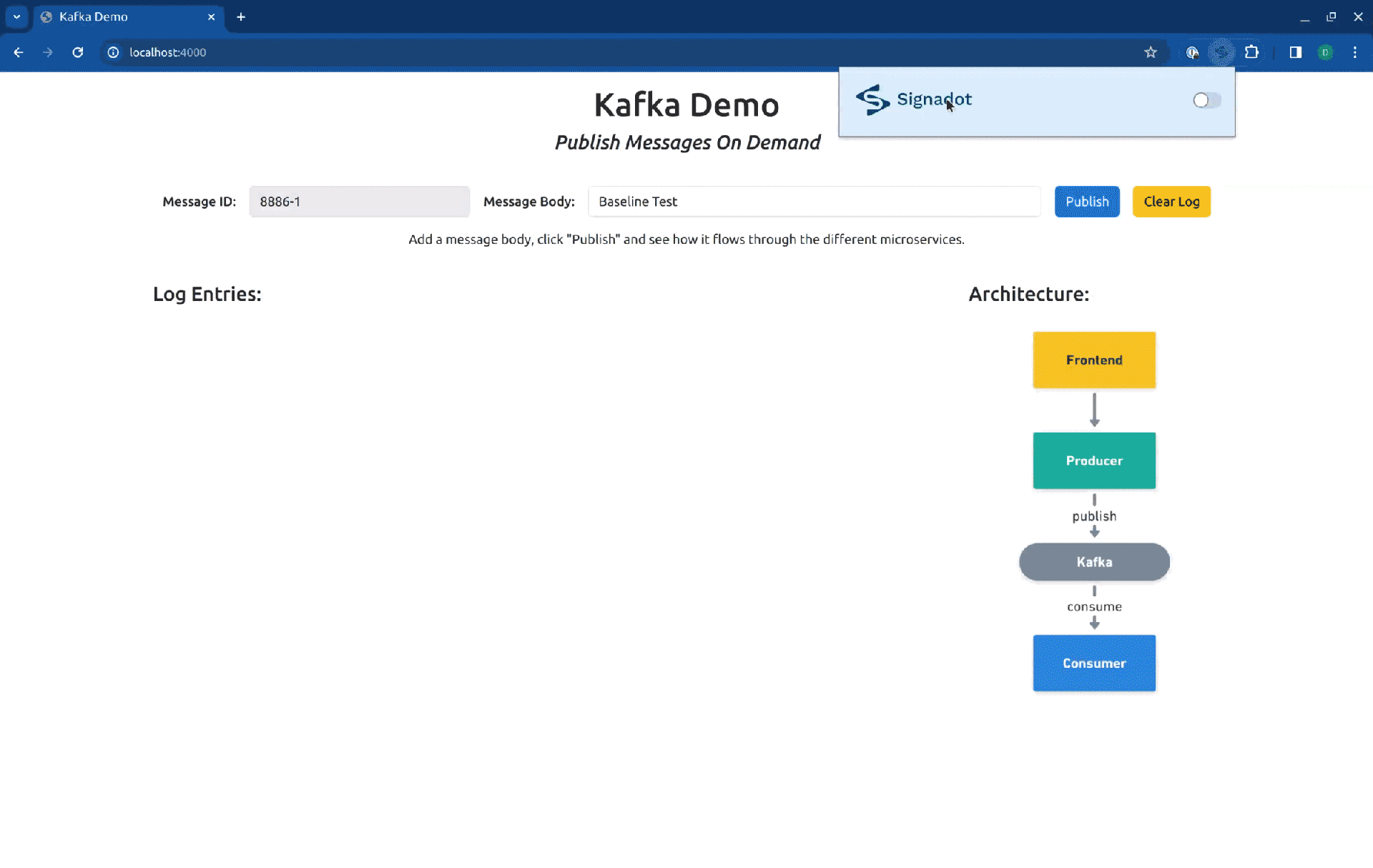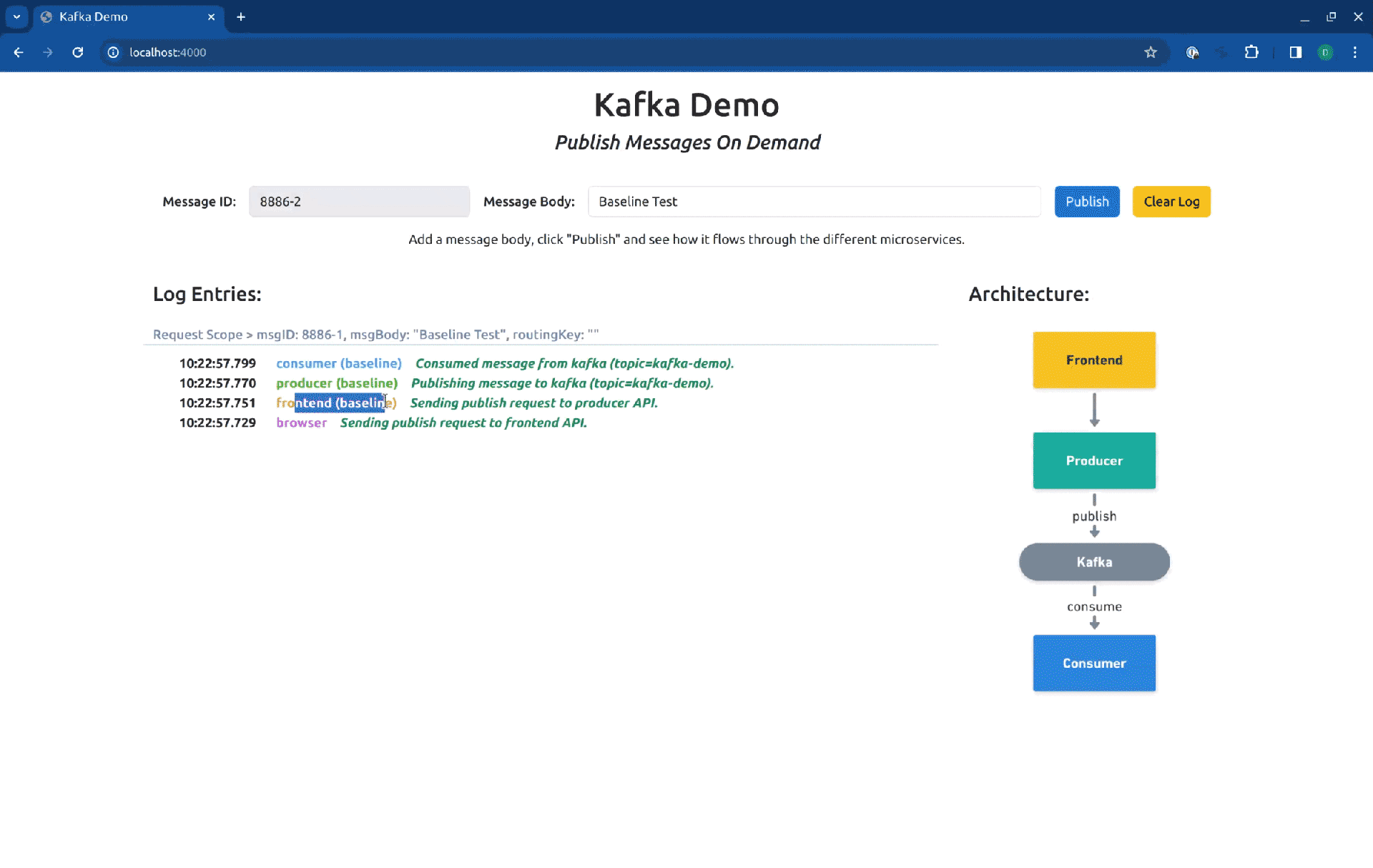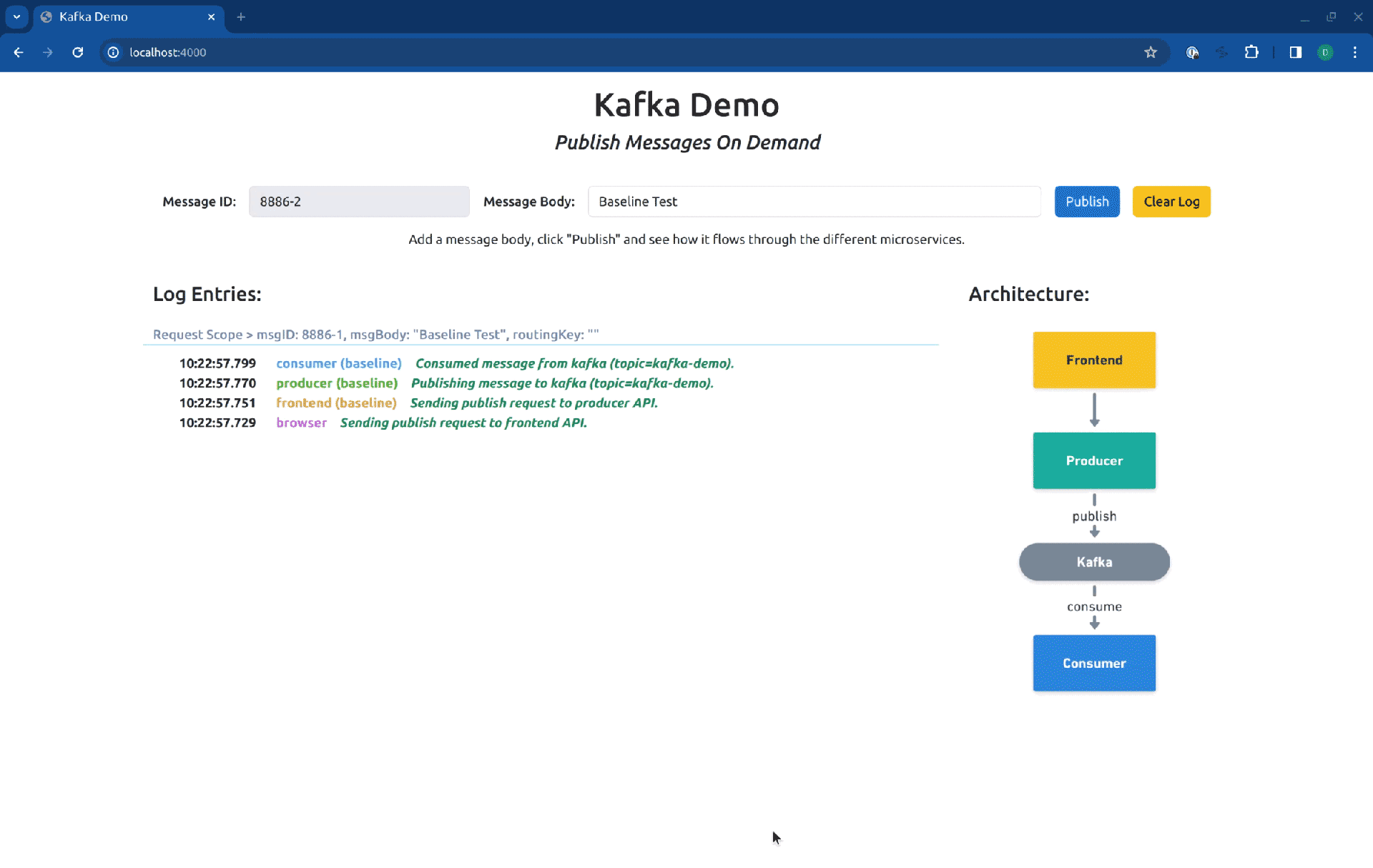
As you can see in the log entries, all the messages came from baseline versions of the workloads. Now, if we switch our routing context to the Sandbox consumer-sbx, you will see that our request is processed by the baseline version of the producer but is consumed by the fork consumer:
Switching now to the Sandbox producer-sbx, our requests will hit the forked producer, but will be consumed by the baseline consumer:
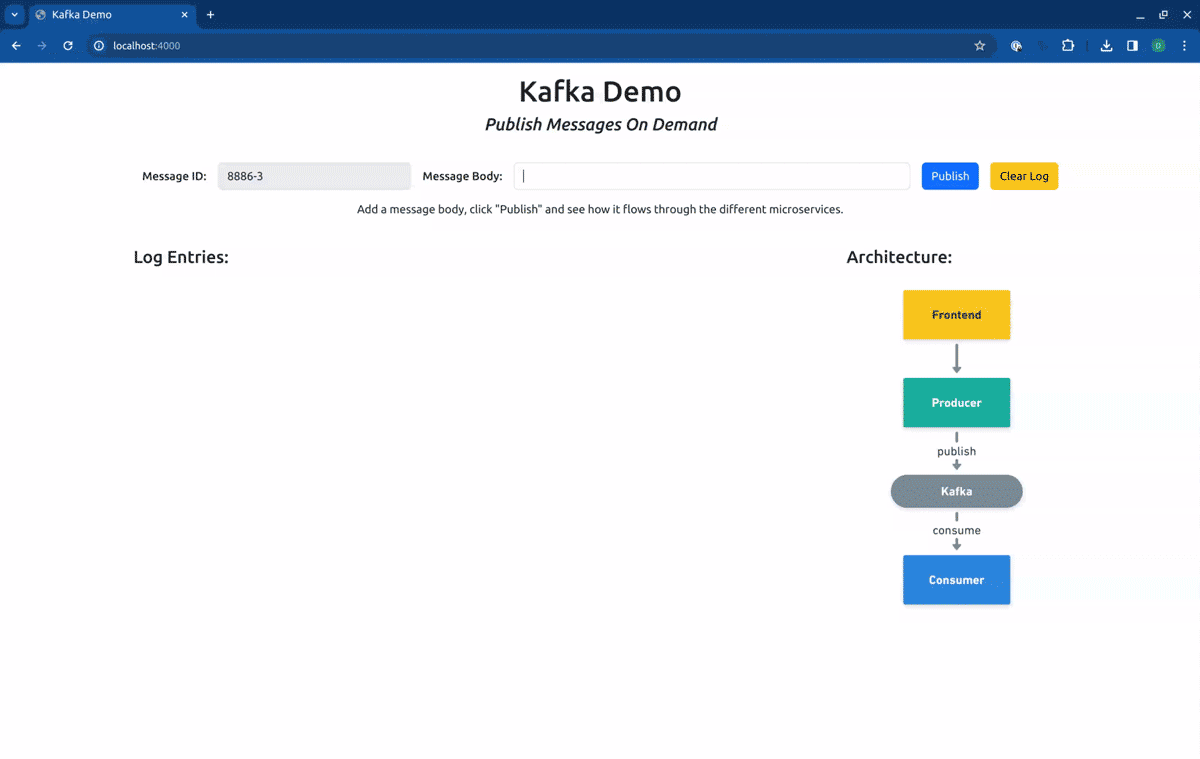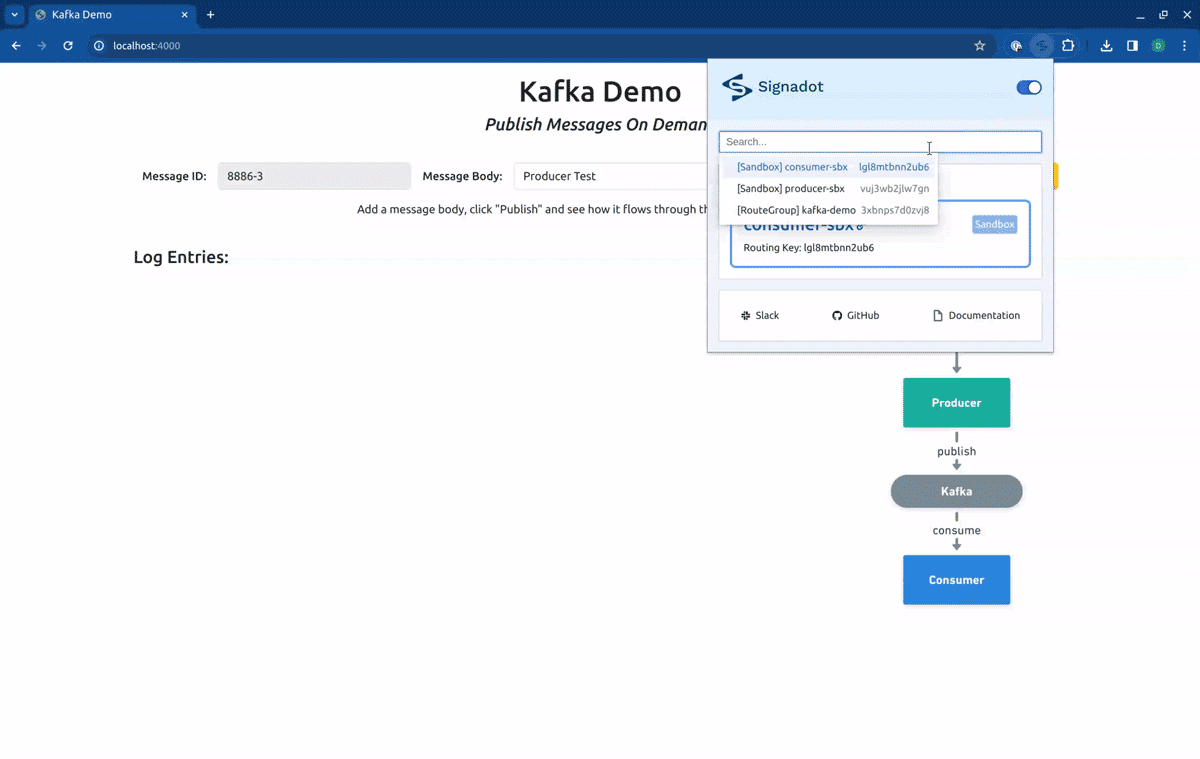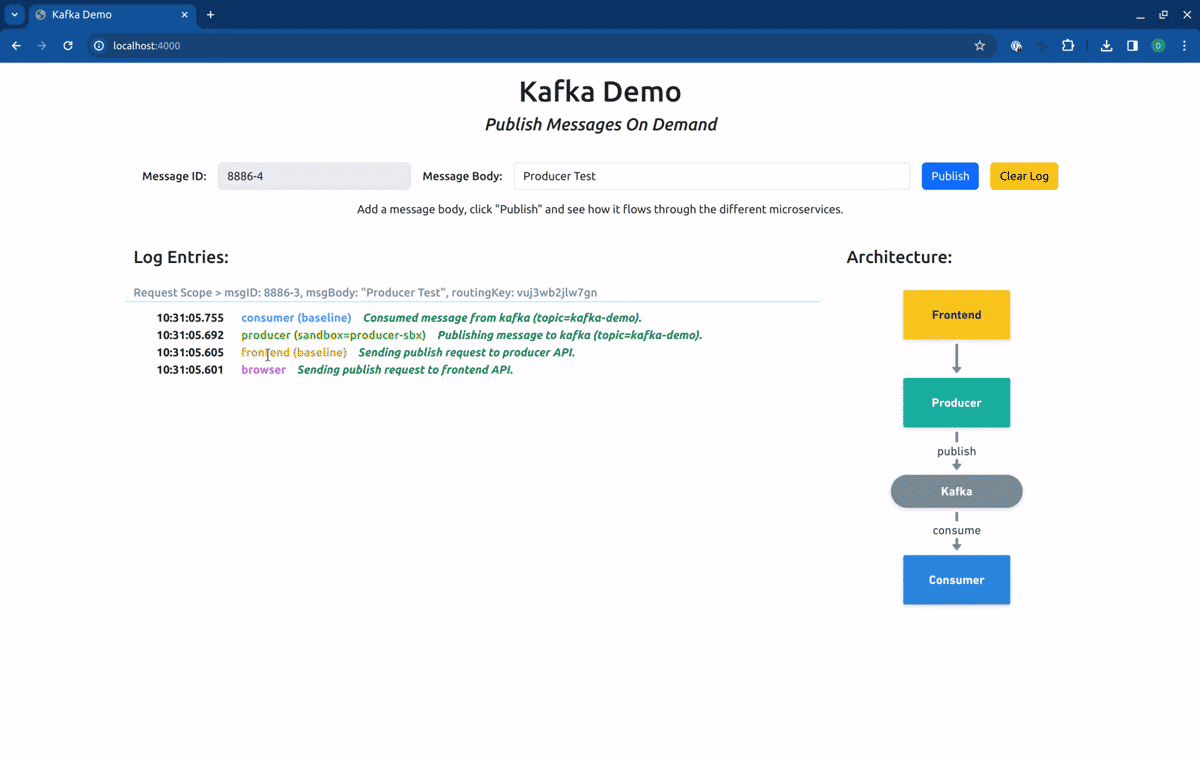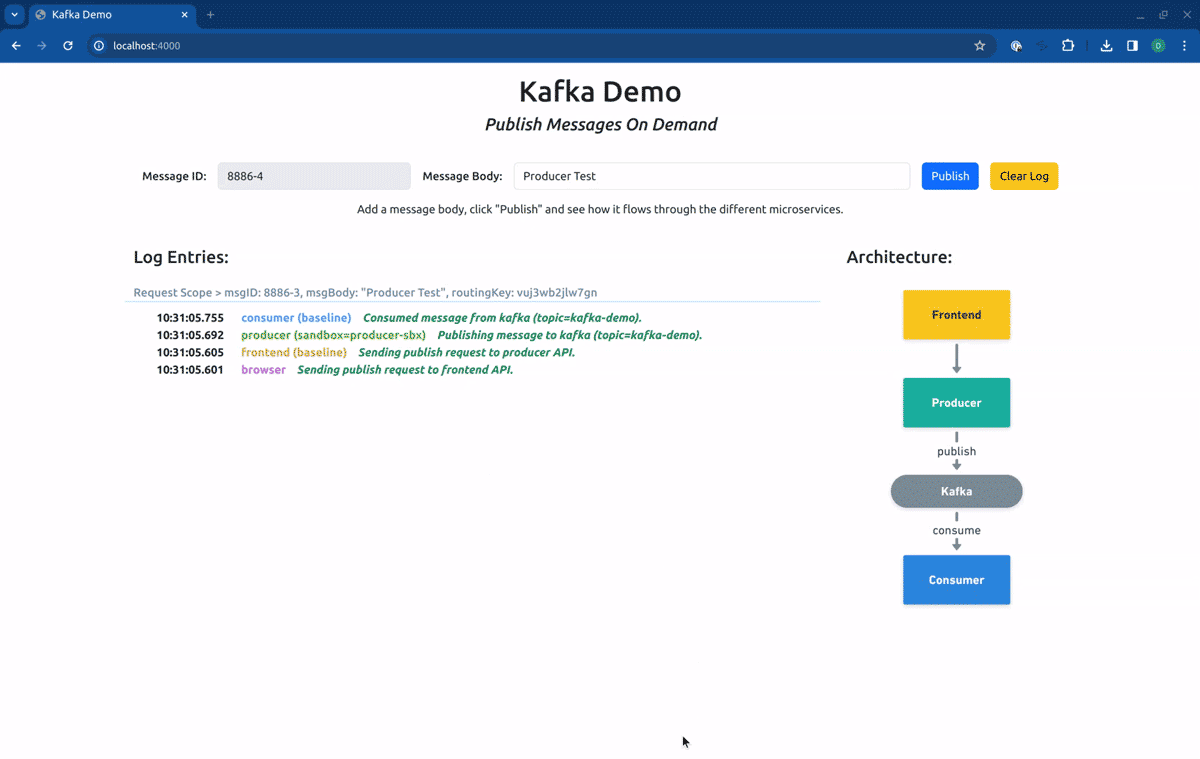
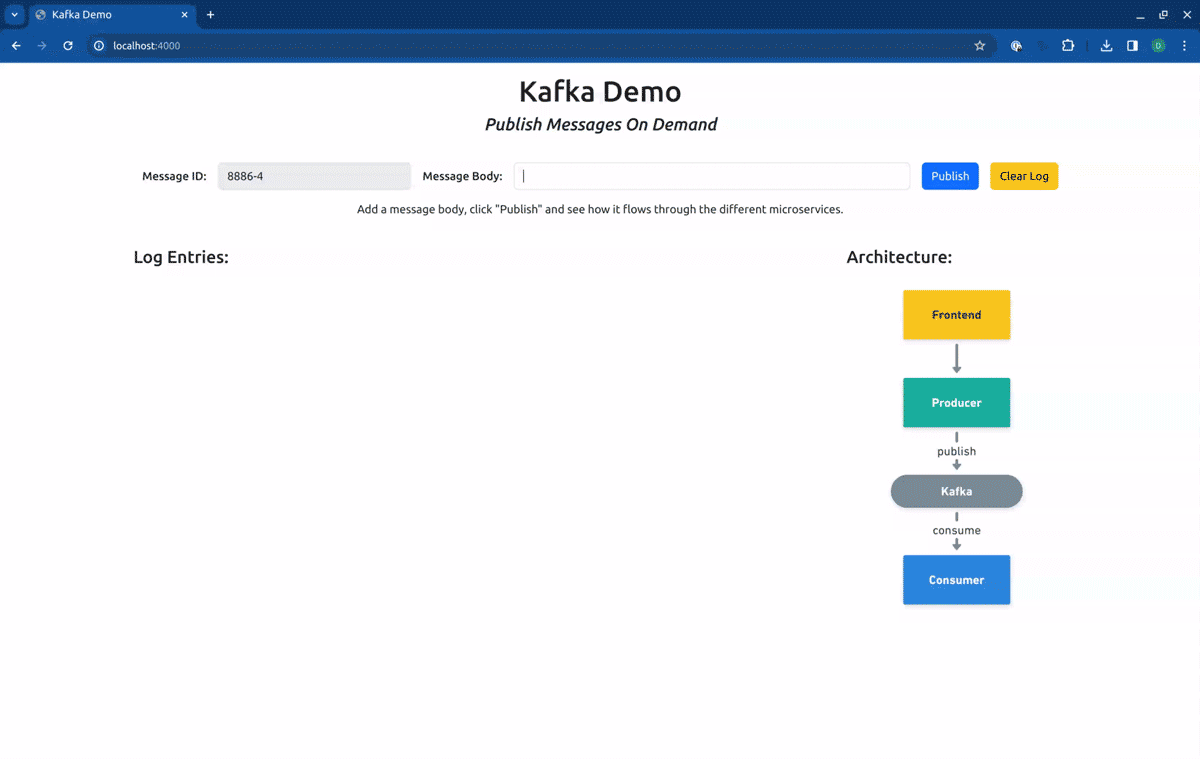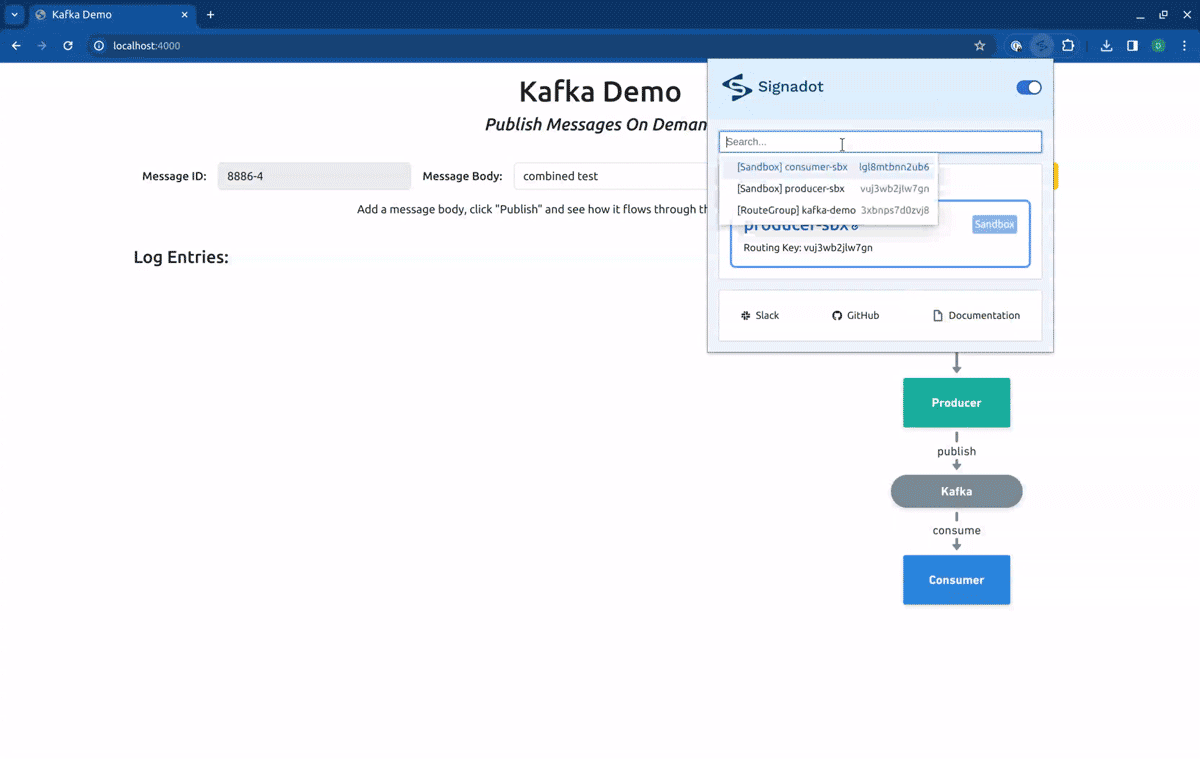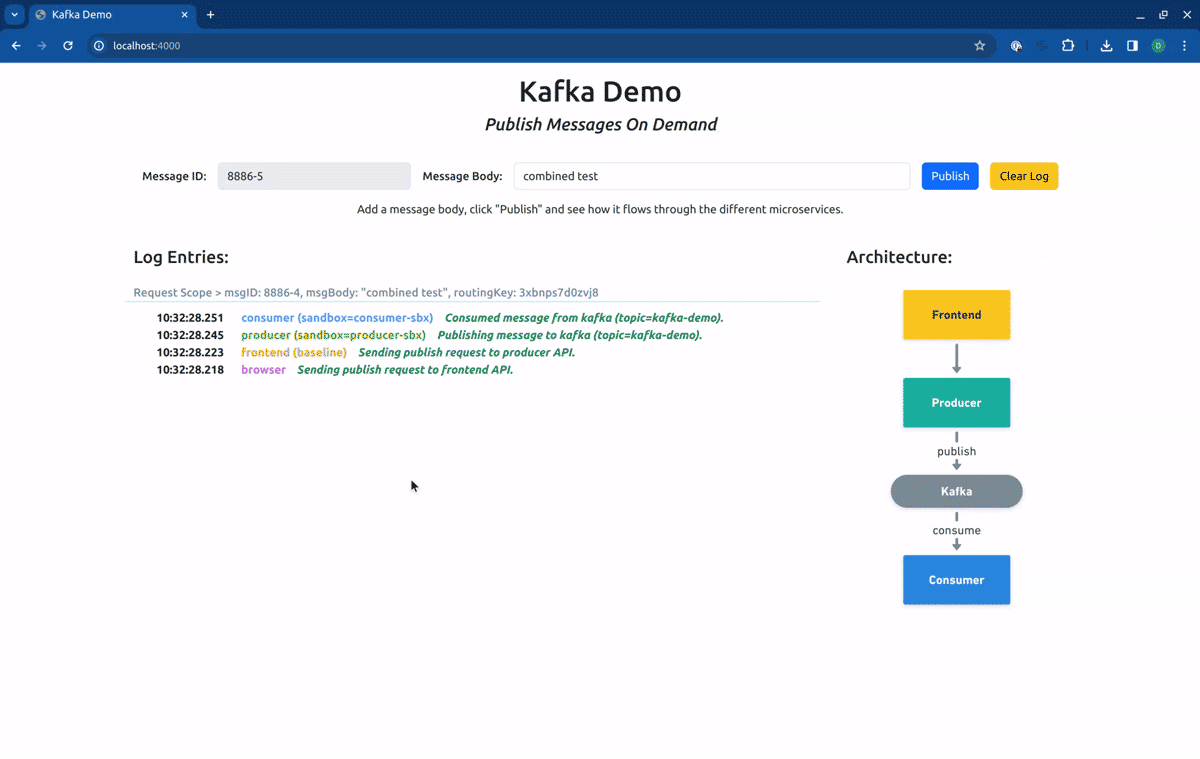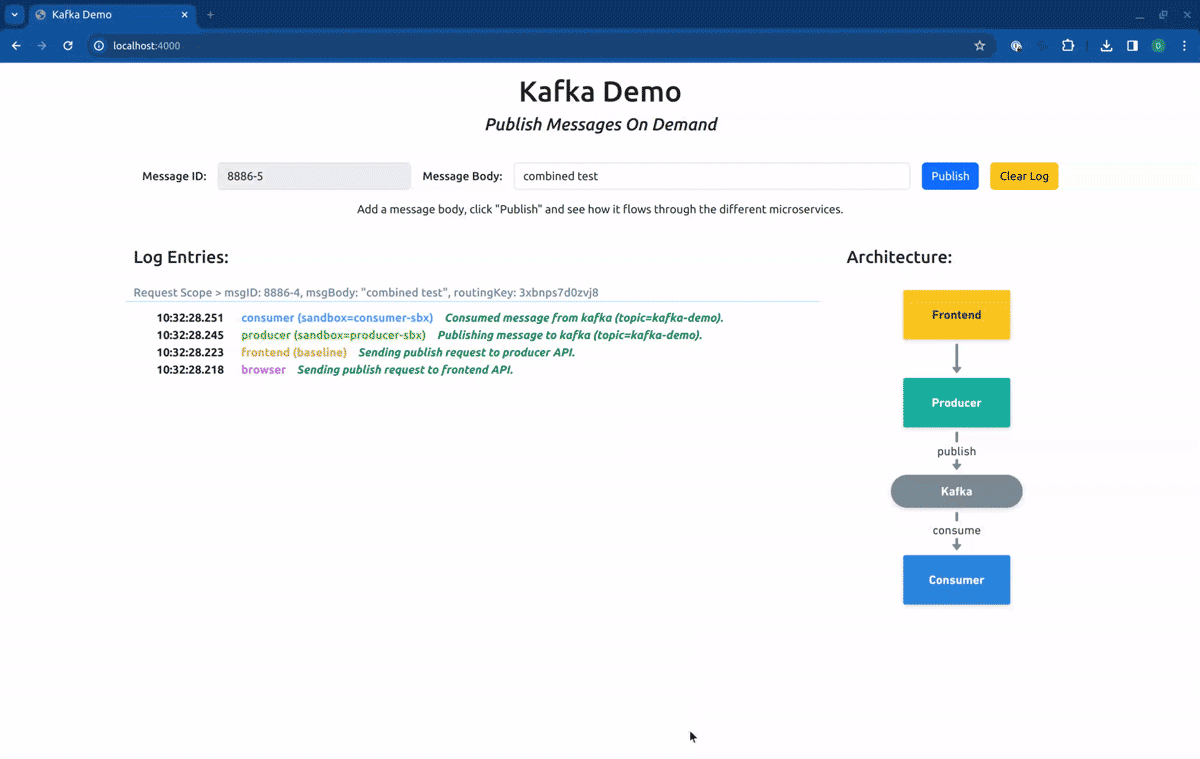
Finally, if we point our routing context to the Route Group kafka-demo, our request will first hit the forked producer, and will be consumed by the forked consumer:
Although this is an extremely basic demo, it allows us to see how it could be applied in a more realistic use case.
Get the latest updates from Signadot

