Explore the complexities of testing Kafka-based asynchronous workflows. Learn about three different approaches, their pros and cons, and how OpenTelemetry can be used for dynamic routing of requests and messages.
Asynchronous architectures are common in cloud native applications as it decouples services and improves the scalability and reliability of the system. A message queue forms the basis of an asynchronous architecture and you can choose one from a myriad of options ranging from open source tools like Kafka and RabbitMQ to managed systems like Google Cloud Pub/Sub and AWS SQS. Among the various options available for a message queue, Apache Kafka is a popular choice in cloud native applications due to its high throughput and low latency capabilities. Kafka’s distributed architecture, fault-tolerance, and scalability make it an ideal choice for building highly resilient and responsive asynchronous architectures.
Since Kafka is a distributed system, setting up a test environment requires setting up multiple components such as brokers, producers and consumers. You would need to configure it correctly with considerations around security, replication, and partitioning. Moreover, setting up services that publish to and consume from Kafka can be time consuming, especially when dealing with different programming languages and frameworks. As a result, setting up an environment that includes Kafka to test end-to-end flows in an isolated manner poses unique challenges.
In this context, we define a Tenant as an actor that needs to run a test scenario in isolation.
Here are three approaches for testing end-to-end flows involving Kafka, each with its own set of advantages and trade-offs in terms of resource isolation and costs.
If you want complete isolation between tenants, you can opt to create a new Kafka cluster for each tenant, including all the producers and consumers. However, this approach can be difficult to manage, especially if you have a resource-intensive Kafka cluster along with many services. Without automation to keep each environment up to date with changes merged to the main branch, these environments can quickly become outdated and require a significant amount of effort to maintain.
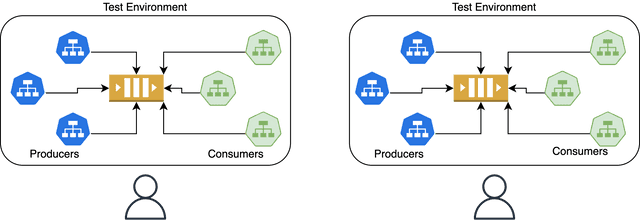
Advantages:
Considerations:
Another option is to use a single Kafka cluster for all tenants and create new ephemeral topics as required for each tenant. You still need to spin up all producers and consumers and reconfigure them to connect to the newly provisioned topic(s) to test end-to-end flows. Although this option can save you costs compared to the previous approach, it may not be practical if you have a complex set of producers and consumers that use Kafka since you will need to duplicate and reconfigure these services for each new topic.
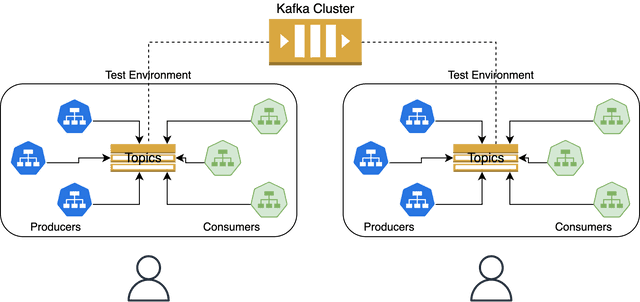
Advantages:
Considerations:
In this approach, you establish a “baseline” environment that includes Kafka and all services, including producers and consumers. This baseline could be a pre-production environment that is continuously updated using a CI/CD tool of your choice. All tenants share this baseline. Each tenant has a mapping to a set of services “under-test”. To isolate tenants from each other, you leverage dynamic routing of requests and messages. You use OpenTelemetry to tag and propagate headers through services and Kafka. Requests and messages are then dynamically routed to specific services based on the value of these headers.
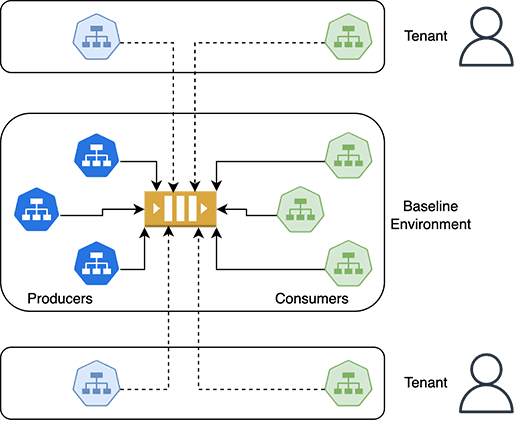
Advantages:
Considerations:
The optimal approach to scale testing cost effectively for asynchronous flows is option 3 above. This is described in detail in the rest of this article.
In this system, a tenant is assigned a unique tenantID with mappings to specific “under-test” versions of services that need to be tested together. Whenever a request or message is sent, it is tagged with the tenantID and dynamically routed to specific versions of services based on the mapping.
As the tenantID is used for routing decisions during synchronous and asynchronous inter-service communication, you need to propagate it across service calls. For synchronous calls, you can propagate it using http or gRPC headers. Next, let’s take a look at how this is done in asynchronous systems like Kafka.
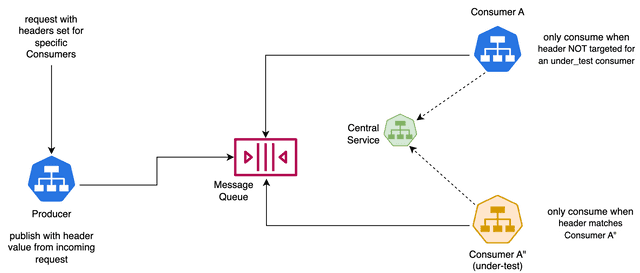
When you use Kafka producers to publish messages, you need to include a message header with the tenantID that identifies the tenant the message is intended for. Typically, this tenantID is obtained from an incoming request or message. Keep in mind that you can have multiple versions of a Producer that publish to the same Kafka broker on the same topics. Each message carries routing information through the tenantID header value.
When you have multiple Kafka consumers that share the same Kafka broker, it’s important to ensure that each consumer only consumes the messages intended for them. This selective filtering of messages is achieved by retrieving the mapping of the tenantID to the set of services from a central service. To do this, a Kafka consumer needs to have logic implemented, as shown in the pseudo-code below.
To have access to all messages in a topic, each of your Kafka consumers needs to connect to Kafka as part of a new Consumer Group. You can have multiple versions of consumers that safely share a single Kafka instance and cooperate on consuming the messages intended for each.
The diagram below depicts this architecture:
To ensure that tenantIDs are propagated through synchronous requests and asynchronous messages, you can use OpenTelemetry (OTel). OTel is an open source Observability framework that supports context propagation, which allows you to propagate context across service boundaries. OTel provides libraries in various languages that instrument frameworks for context propagation including custom key-value pairs in the form of Baggage. This provides a convenient mechanism to propagate tenantID across synchronous calls and asynchronous messages, including Kafka. OTel also offers auto-instrumentation for dynamic languages such as Java, Node.js, and Python, which you can use to enable context propagation without changing application code.
To instrument Kafka producers and consumers to propagate context through Kafka, you can refer to the concrete example provided in the OTel documentation. This example shows how you could propagate tenantID from publishers through Kafka to the consumers.
Let’s take an example of services A, B, C, D and Kafka as the baseline. You wish to test an end-to-end flow with new versions of services B” and C”. Assume there is a central service that manages tenants and mappings, and all services are assumed to have OTel instrumentation to propagate tenantIDs. Here’s how you can set up a tenant to test your changes end-to-end:
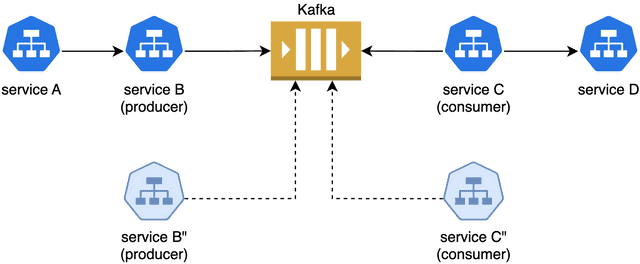
The above example shows an end-to-end testing scenario for one tenant. Such a system can support a large number of concurrent tenants without duplicating infrastructure. Next we look into a few additional considerations when implementing such a multi-tenant system.
Here are some additional considerations around the solution detailed above.
The proposed solution may not be sufficient for testing certain types of flows, such as batch jobs that don’t involve external requests. For example, if a batch job reads rows from a database, processes them, and publishes messages to Kafka, the tenantIDs may need to be available in the rows fetched and propagated through Kafka headers.
To optimize performance, it’s recommended to cache the result of the mapping retrieved from the central service locally in all the Kafka consumers. However, this caching introduces the possibility of stale data since the mapping could have been updated in the central service. It’s important to manage the cache properly to ensure cache coherency across Kafka consumers.
To connect a Kafka consumer with a unique consumer group name, you can choose to either set it up in your application code or via the Kafka CLI. Remember that when you delete the tenant, you should also delete its corresponding consumer group to free up resources in the Kafka broker. It’s important to make sure that the lifecycle of your Kafka consumer groups is synchronized with that of your tenants.
You need to consider setting the offset for the Kafka consumers based on your specific use-case. A common scenario is to use the offset of the baseline consumer to process the latest messages.
Scaling environments that use asynchronous systems like Kafka across multiple tenants can present unique challenges. There are several approaches to address them, each with its own advantages and trade-offs in terms of resource isolation and costs. One of the most cost effective methods is to share a common baseline environment across tenants. This approach allows for scalable, isolated testing with minimal operational overhead and eliminates the issue of outdated environments. By utilizing OpenTelemetry to propagate headers through Kafka and by dynamically routing messages, you can achieve efficient scaling of Kafka environments with high levels of isolation and flexibility. It’s worth noting that this approach can be easily extended to other message queues, making it a versatile solution for asynchronous applications.
If you would like to learn more, check out Signadot’s Documentation or continue the discussion on our community Slack channel.
Get the latest updates from Signadot

