Testing asynchronous systems in distributed environments is no small feat, especially with the challenges of coordination, interference, and infrastructure overhead in shared or duplicated setups. But what if developers could isolate their tests seamlessly without the complexity or cost? Enter sandboxing with dynamic traffic routing—a game-changer for microservices architectures. By leveraging headers and tools like OpenTelemetry, this approach routes traffic intelligently, ensuring test changes don’t disrupt others. Developers at companies like Brex and DoorDash are already reaping the benefits of faster iterations, lower costs, and hassle-free testing workflows.
Originally posted on The New Stack.
With sandboxing, developers can see the impact of their changes without disturbing other developers’ tests or regular traffic flow through the system.
In modern distributed systems, asynchronous communication patterns have become increasingly prevalent. While there are many message queue systems available today — from Apache Kafka to RabbitMQ, or cloud services like Google Pub/Sub and AWS SQS — we’ll focus on Apache Kafka as a concrete example. However, the patterns and challenges we’ll discuss are applicable across different message queue implementations.
Message queues form the backbone of many microservices architectures, implementing various patterns to handle different use cases. In a many-to-one pattern, multiple producers send messages to a single consumer, which is common in data aggregation scenarios.
Many-to-many patterns enable multiple producers to communicate with multiple consumers, which is useful in event-driven architectures. One-to-many patterns, where a single producer broadcasts to multiple consumers, are often seen in notification systems.
Testing changes in asynchronous systems presents unique challenges, particularly in shared environments where multiple developers work simultaneously. Consider an e-commerce platform where an order processing service publishes events that trigger multiple downstream processes like payment processing, inventory updates and shipping notifications. When developers need to test changes to any service in this workflow, they face significant challenges.
In shared environments, multiple developers testing concurrent changes often interfere with each other’s work. A developer modifying the order processor might affect another developer testing changes to the payment service. When tests fail, it becomes difficult to determine if the failure is due to their changes or interference from other ongoing tests. Schema changes are particularly challenging, requiring careful coordination across teams to avoid breaking things for existing consumers.
Developers spend considerable time coordinating testing windows with other teams, waiting for others to complete their testing, and debugging issues that may not be related to their changes. This leads to slow feedback cycles and reduced productivity. The lack of isolation between different developers’ changes makes it hard to run comprehensive integration tests with confidence.
One approach to address these challenges is spinning up complete, isolated environments for each developer. However, this approach comes with its own set of problems. For a system like Kafka, each environment requires replicating the entire message queue infrastructure, including brokers, cluster management components and all the associated services. This quickly becomes prohibitively expensive and complex to maintain. Setting up these environments takes significant time, and the infrastructure costs for running multiple complete environments at scale can be substantial.
Both approaches present significant drawbacks from a developer experience perspective. Shared environments lead to testing interference and complex coordination requirements, while duplicated environments introduce high costs and maintenance overhead. This creates a clear need for a better approach that can provide the isolation developers need without the overhead of complete environment replication.
Leading technology companies have adopted a more efficient approach using dynamic traffic routing and sandboxes. A sandbox is an isolated testing environment that allows developers to test their changes while sharing most of the underlying infrastructure with other developers.
Instead of duplicating entire systems, this method uses request headers to route traffic to specific service versions. One common approach to propagate these headers through the entire request chain is using OpenTelemetry libraries, which provide built-in context propagation capabilities. While OpenTelemetry is commonly known for distributed tracing, its context propagation capabilities alone provide significant value, which we use in this approach.
For request routing, we only need the context propagation functionality — implementing distributed tracing is not required. For synchronous communication between services, dynamic routing can be implemented at the infrastructure layer using service mesh or sidecars in Kubernetes environments. A central “Route” service stores the mapping between services and routing keys, which the infrastructure layer consults to make routing decisions.
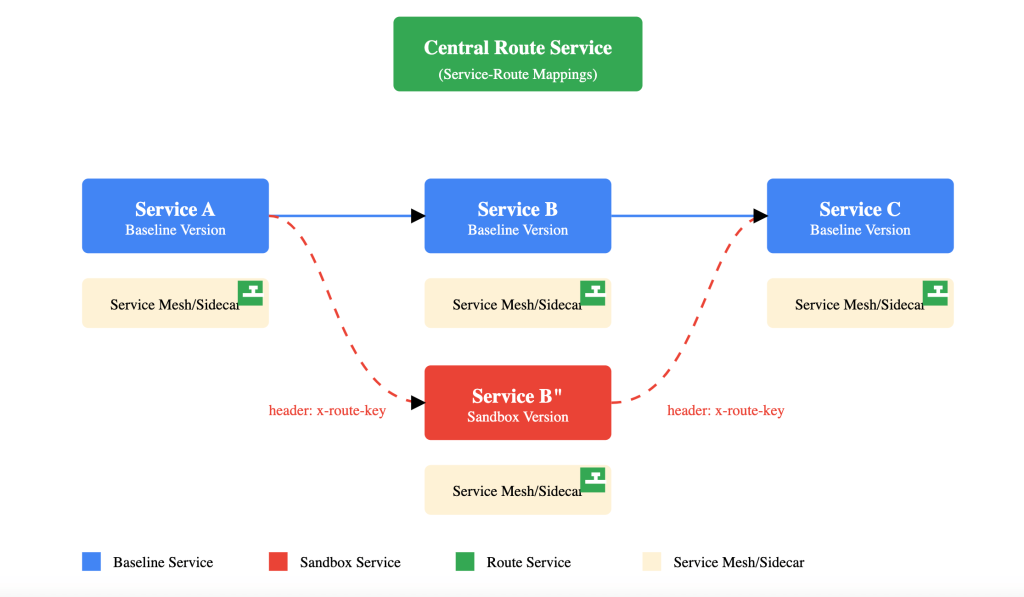
Request flow being routed to sandboxed Service B” based on request headers
For asynchronous systems, there are special considerations that we describe below. The solution involves three key components working together to ensure proper message routing in asynchronous flows:
First, producers must be instrumented to include routing information in message headers. When a request initiates the message production, the routing context is propagated from the incoming request.
Second, when a sandboxed version of a consumer service starts up, it creates a new Kafka consumer group. This ensures all messages are received by both baseline and sandbox consumers, with the consumer group name typically derived from the sandbox ID for traceability.
Third, and most critically, is the selective message processing logic. Both baseline and sandbox consumers receive all messages but must decide which ones to process. Here’s how this decision is made:
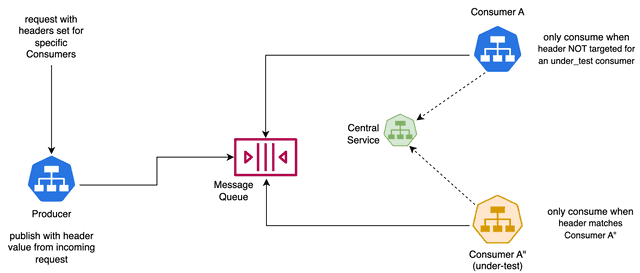
Kafka Producers and Consumers using headers for selective consumption
This logic ensures proper message routing even in complex scenarios.
The above approach needs adaptation for certain common message queue patterns. When using message queues with change data capture (CDC), such as Debezium with Kafka, the producer reads from a database transaction log. In these cases, the source database records need to include routing information, typically in a metadata column, which the CDC producer can then include in the message headers. This ensures proper routing even for database-initiated events.
For systems that process messages in batches, routing decisions need to be made at the batch level. Messages with different routing contexts should be processed in separate batches, with the batch processor maintaining routing context across the entire batch life cycle. This becomes particularly important in high-throughput systems where batch processing is crucial for performance.
From a developer’s perspective, testing changes to asynchronous workflows becomes remarkably straightforward with this approach. Let’s say a developer is modifying a service that consumes order events from Kafka and updates the shipping system. Here’s their experience:
First, they create a sandbox for their modified service through their platform team’s provided tooling. Behind the scenes, the platform handles all the necessary setup — deploying the service, setting up consumer groups and setting up routing — but the developer simply needs to request a new sandbox.
To test their changes, they trigger a test order through the regular application interface or API, including a simple header or parameter that routes traffic to their sandbox. The platform’s instrumentation automatically ensures this routing information propagates through the entire system, from the initial request, through the message queue, and to their modified service.
The developer can then observe how their changes process the test order, while other developers’ tests and regular traffic continue flowing through the system undisturbed. All the complexity of message routing, consumer group management and context propagation is handled by platform-provided libraries and infrastructure, making the testing experience seamless for developers.
This enables developers to quickly iterate on their changes without worrying about interfering with others or managing complex infrastructure. They can focus on their service logic while the platform ensures their test traffic flows correctly through the asynchronous system.
Effective testing of distributed systems doesn’t require massive infrastructure duplication. With the right architecture and tools, teams can achieve faster, more reliable testing while reducing costs and improving developer productivity.
Companies like Brex, DoorDash and ShareChat have successfully implemented this approach using Signadot, which provides an out-of-the-box solution for both synchronous and asynchronous testing scenarios. To learn more about implementing this pattern in your organization, visit signadot.com and join our community Slack channel.
Get the latest updates from Signadot

