Discover how OpenTelemetry enables the creation of lightweight, efficient sandboxes for microservice testing in Kubernetes. The post discusses distributed context propagation and its benefits beyond telemetry and tracing. Learn about the advantages of sandboxes over traditional environments, including resource efficiency and quick setup.
The OpenTelemetry project was announced in 2019 as the coming together of two efforts that existed prior to that - OpenTracing and OpenCensus, with the goal of becoming a single open standard for extracting telemetry from distributed microservice-based applications. The project is a collection of specifications, tools, and libraries intended to help collect telemetry from applications in the form of logs, metrics, and traces, which can then be forwarded to any observability tool that supports aggregating, visualizing, and introspecting this data.
In this post, we will explore a new use-case that makes use of OpenTelemetry (abbreviated as OTel), specifically distributed context propagation that is enabled by OTel, in order to create lightweight environments called sandboxes that can then be used to enable various forms of microservice testing in a scalable fashion. We will also look at what kinds of applications this model works most naturally with, and how it can help get high-quality testing feedback early in the development lifecycle.
One of the use cases that OTel was designed for is tracing. Tracing provides an understanding of how a user or application request is processed by a distributed system that involves many separate components.
Each individual microservice, as it handles and processes a request, emits some information called a “span” that contains some context regarding which request it is processing - and once all these spans are sent to some backend, they can be stitched together to inform you of the whole request flow, called the “trace”. A trace can be used to understand what happened to a specific request, and also in an aggregate context to discover and address patterns that might be affecting certain subsets of requests. This information about the path taken by a request through a system comprising multiple microservices is effective at isolating and deducing the root cause of production issues quickly when they occur.
When we look at the diagram below, we can see that each individual service is only emitting its own “span” which pertains to how it processed the request locally. So, to tie the spans that belong to a single request into a single trace, we need some form of context to be propagated across these services that identifies the request itself, which is referred to as the trace context.
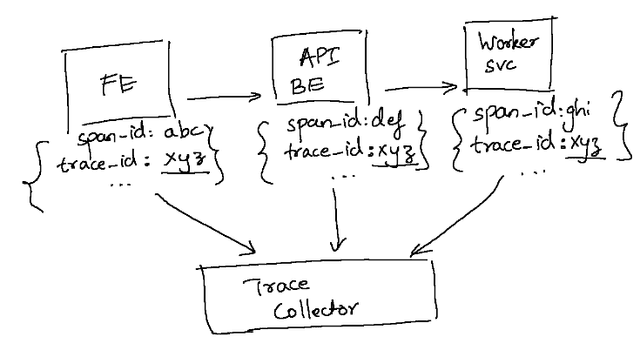
OTel enables this via its libraries by taking care of passing the identifier of the trace from service to service along the entire chain of synchronous/asynchronous requests. What’s more, for some dynamic languages, it simply needs dropping in the corresponding OTel library which “auto-instruments” the byte code to perform distributed context propagation transparently.
This idea of propagating a piece of context along a request flow, while it has had its genesis in tracing, is not specifically tied to tracing. It is a more general mechanism that could be leveraged to propagate more than just trace-related information as needed between microservices. The baggage specification makes this clear in its wording.
This specification defines a standard for representing and propagating a set of application-defined properties associated with a distributed request or workflow execution. This is independent of the Trace Context specification. Baggage can be used regardless of whether Distributed Tracing is used.
This specification standardizes representation and propagation of application-defined properties. In contrast, Trace Context specification standardizes representation and propagation of the metadata needed to enable Distributed Tracing scenarios.
Source: https://www.w3.org/TR/baggage
So, now, we start to make use of this mechanism to realize use cases that go beyond just telemetry and tracing.
A sandbox is a type of lightweight environment that can be used to test and verify changes to a subset of the microservices within the stack. One of the key differences between a sandbox and a traditional environment is that a sandbox makes use of a shared set of unchanged dependencies, called the “baseline” in order to test a few services that have changed.
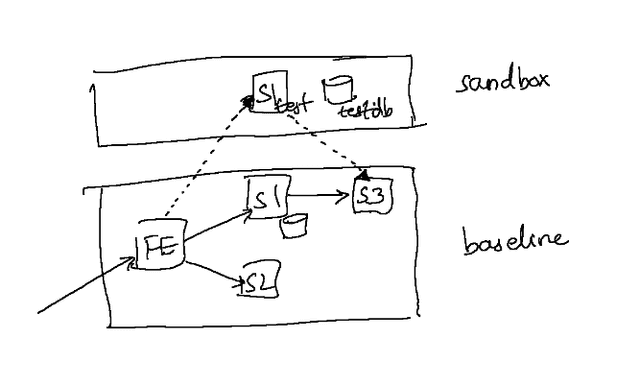
This property makes a sandbox highly resource efficient and quick to set up. This in turn means that one can spin up a sandbox to test a single commit, or a single change to each microservice, something that becomes cost prohibitive with a traditional environment with microservices that are at even moderate scale (>20 or so).
Another key advantage of this approach is that these sandboxes can be deployed into an existing environment - say staging or production, to test changes against the most up-to-date dependencies thereby removing the issues of stale dependencies and having to re-test in “higher” environments repeatedly due to differences between them.
In the below sections, we will look at how we can leverage distributed context propagation from OTel to create sandboxes within Kubernetes.
Once our applications are able to carry arbitrary pieces of context across requests thanks to OTel libraries and instrumentation, we can now start thinking of using that to isolate requests and their effects from one another.
We’re looking to create sandboxes by leveraging request level multi-tenancy. This is done by assigning each request to have a particular “tenancy”. Tenancy simply refers to an identifier associated with each request that tells the system how to handle & route a particular request. In the below examples, the tenancy is specified by the “tenant” header (or more generally, L7 protocol metadata), and has a value that identifies which specific test version of the service it should be routed to. This tenancy metadata is passed along between services using the baggage mechanism in OTel - and makes use of HTTP / gRPC headers under the hood.
Taking a simple microservices application consisting of a single frontend and backend, we can set up the following:
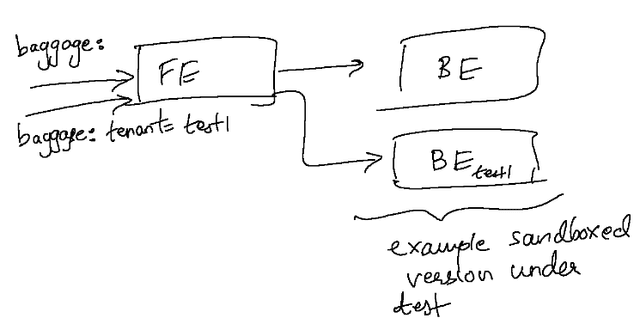
We can teach our frontend to route the outbound request it is making to the backend conditionally based on the tenancy. In Kubernetes, making the routing decision is trivial since there are several mechanisms available to handle it without the application being involved in the decision. For example, a service mesh (like Istio) could be used, which makes such routing operations easy to express in the rules of the mesh itself. It’s fairly trivial to also create a sidecar container that makes use of envoy or custom code that can intercept requests and proxy it transparently at each microservice.
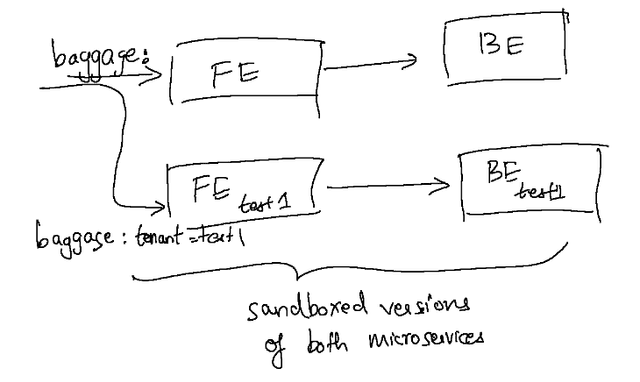
This setup we created above would also scale to testing multiple workloads under test as well. This setup could easily be set up within an existing staging or a production cluster with minimal effort. Staging and production often already have a Continuous Deployment (CD) process that updates the stable versions of the services (baseline), and deploying these sandboxes within the same cluster allows us to reuse those dependencies when they’re not being tested.
Simply with request isolation shown above, this sandbox can be used for testing changes to a stateless service, running API tests, etc. However, it is still limited in that we haven’t yet addressed the isolation of data mutations that may have side effects, isolation of asynchronous workflows through message queues, or calls to third-party APIs. In the below sections, we’ll address these considerations to make sandboxes more robust and able to support more kinds of testing in a microservices environment.
An essential step in performing more complex testing across more use cases using this approach is addressing state isolation. One thing to note here is that not every use case involving microservice testing requires additional state isolation. For example, in running API or E2E tests for a particular flow either manually or using automation, if within the particular flow, we are able to create and clean up entities that we make use of in our test, then we have already realized a hermetic test without actually needing additional state isolation.
However, there are cases where we need additional isolation, like when a DDL change is performed on a datastore, or if we may perform some mutations that have side effects. In these cases, we may want to deploy an isolated version of the data stores that may be affected and make our sandboxed workloads use them instead of what’s being used by the baseline environment.
We’ve seen it be far more effective in practice to make use of logical isolation rather than infrastructure isolation wherever possible. For example, in databases like MySQL and PostgreSQL, as well as most managed cloud databases there is a built-in notion of logical isolation that is provided by the data infrastructure itself. This choice of logical isolation keeps sandboxes lightweight, resource efficient, and still able to spin up in seconds, while proving sufficient for most cases. It is of course always possible to spin up new physical infrastructure to associate with a sandbox if it is necessary, but in practice, we’ve found this need to be very rare.
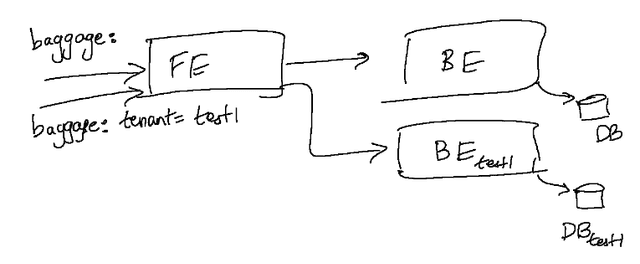
Bringing up the infrastructure is only a part of the solution; seeding the data is key - and must be performed at/before the time the environment is brought up. We can either tie the lifecycle of all these ephemeral datastores to the lifecycle of the environment itself or choose to set up and maintain pre-warmed datastores that are requested and provided to the test versions of our services on demand. The latter approach of using pre-warmed test datastores can help in having high-quality data ready; and in practice, the number of such test data stores that need to be kept on hand is not particularly high even for a large microservices stack. Some more advanced users of the sandbox approach have gone further and implemented mechanisms to correlate the tenancy to specific kinds of datasets, like Uber for example in their blog post on SLATE.
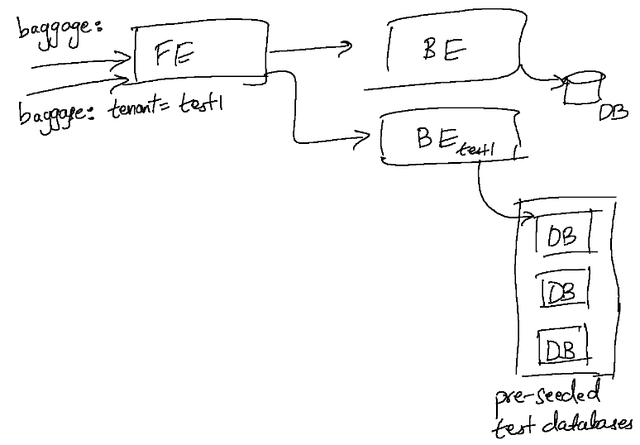
Using ephemeral isolated data stores, we can provide high quality data to develop / test with, while ensuring that no side effects are visible outside the environment. The idea of using logical isolation especially helps with allowing us to scale the number of sandboxes while incurring minimal additional infrastructure or operational cost. In contrast with the prevailing notion of an environment choosing the highest isolation level as the default, we can choose the most appropriate type of isolation for sandboxes depending on the use-case and nature of the application.
Message queues are ubiquitous in the modern microservices stack and present an interesting challenge when it comes to these sandboxes. Considering message queues, most (if not all) implementations of a message queue allow setting some headers/metadata in messages. This implies that the messages themselves contain some information about the identity of the request/flow from where they originate, which gives us some ideas on how we can do routing of messages.
Logical isolation is typically preferred with message queues as well, as opposed to physical isolation. So, for example, if Kafka were our queue, we would prefer to set up separate topics, as opposed to standing up new isolated Kafka clusters.
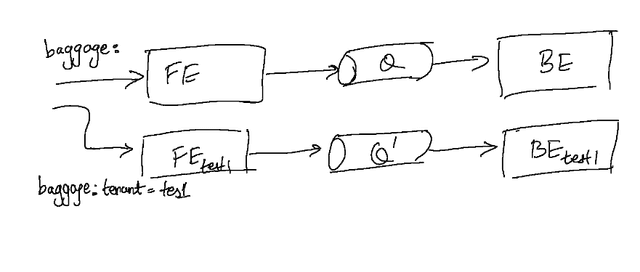
While this solution is guaranteed to work, practically there are many producers and consumers in a large microservices environment making this less than ideal - since it may end up requiring us to stand up each microservice in isolation anyway. A cleaner method of isolation is teaching the consumers to consume more selectively and in a “tenancy-aware” manner.
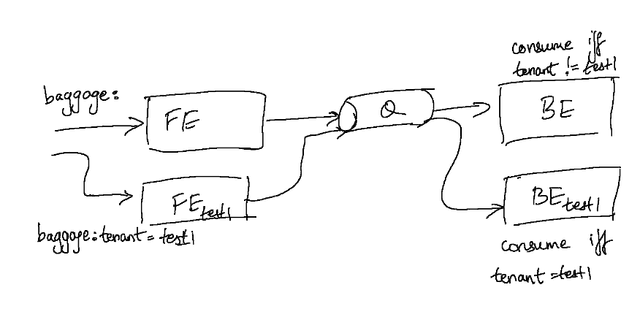
This approach of making consumers tenancy-aware requires some change at the application layer. The functionality can be easily encapsulated into a “message-router” library that can be used alongside the consumer clients. This library would make a decision of consuming or dropping a message based on the identity of the consumer service (is it baseline? which sandbox does it belong to?) and the message metadata containing tenancy information. The library would need to know information about the state of different sandboxes in the cluster in order to make this decision at each consumer, which requires that it interface with some routing controller (or service mesh) that is running within the Kubernetes cluster.
This approach solves a long-standing problem of message queues being notoriously hard to test in a microservices stack, by providing a clean manner of multiplexing different flows using tenancy-aware consumers, and requires no additional infrastructure setup, which makes it very quick to set up.
The modern microservices stack makes use of many third-party APIs and external services to provide important functionality, such as payments, integrations, etc, which may interface with microservices in Kubernetes using external API endpoints and webhooks. In third-party APIs, the method of propagating tenancy information varies depending on the system.
In many cases, these APIs are simply fire-and-forget or have side-effects that are controlled by the application itself, in which case tenancy propagation through the external system may not be required.
In systems where a callback or a webhook is expected from the external system to perform some additional processing in our microservices, query parameters in the HTTP callback URL can be used to propagate tenancy information. The routing mechanism inside the Kubernetes cluster would look for a certain special query string that contains tenancy information and use that to route those callback requests to the appropriate sandboxed workload.
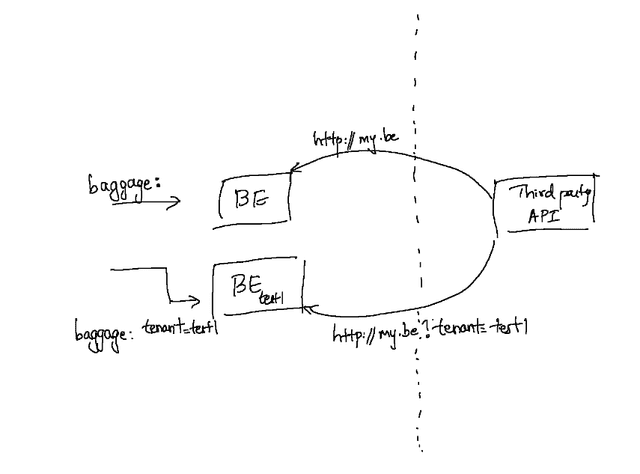
This mechanism in practice often requires some minor application layer modification. The microservice must also be aware of its own tenancy - i.e. have information about the sandbox that it belongs to, so that it can set the appropriate tenancy metadata on callbacks.
The sandbox approach has been realized at scale at Lyft, Uber, and Doordash across hundreds of microservices; which allows for a very effective and scalable mechanism to test and iterate quickly. We’ve learned some lessons in working with organizations, to help them adopt sandboxes in their own infrastructure.
In practice, the simplest way that we’ve found for an organization that wants to start adopting this approach, is to start by integrating sandboxes into the CI process for a few microservices. These sandboxes can be created within an existing staging environment, which involves very little additional setup, and removes bottlenecks associated with a shared staging environment. From this point, it’s easy to extend sandboxes to pre-merge testing of changes across different microservices, E2E testing, and performance testing, as OTel adoption grows within the organization and gaps in context propagation are filled. As adoption grows, it is typical to see the need for additional test environments or staging environments fall sharply as more and more use cases can be addressed quicker and easier using sandboxes.
We’ve found also that pre-merge testing of services with one another, i.e. bringing together test sandboxes that belong to different services and running traffic through them is extremely useful in the development lifecycle, and far quicker in terms of development iterations and feedback than post-merge testing as is currently common.
Testing using sandboxes in production is the holy grail, which comes with the ability to eventually do away with staging entirely. This is eventually possible once the tenancy controls and data isolation mechanisms are sufficiently mature within an organization, but is most often not the best starting point for an organization looking to use sandboxes.
While the majority of microservice communication patterns fit well in this paradigm, there are some, i.e. testing Kubernetes infrastructure components, or components that use low-level networking over custom protocols which prove difficult. For these cases, the more traditional way of setting up environments, or a different method of isolation may be more appropriate than using sandboxes.
In this post, we explored the paradigm of sandboxes which are lightweight environments that make use of request-level isolation to provide scalable testing of microservices. We looked at different technical aspects in realizing an effective sandbox solution internally, such as propagating context using OTel, request routing, state isolation, dealing with message queues and third-party APIs. Finally, we also looked at some practical considerations for an organization that is looking to implement sandboxes internally.
The sandboxes approach is already being used effectively in the industry to help speed up and improve the development lifecycle. We at Signadot are building a Kubernetes-native solution that makes it easy to create and deploy sandboxes and we’re excited to help make this possible. You can read more about Signadot’s approach in our documentation or come talk to us on our community slack channel!
Get the latest updates from Signadot

