The blog post discusses the challenges faced by Uber and DoorDash in their quest for efficient testing in production. Uber, dealing with unreliable end-to-end tests and conflicts over staging environments, developed SLATE (Short-Lived Application Testing Environment) to create on-demand ephemeral testing environments. This improved isolation and developer velocity. On the other hand, DoorDash, striving for faster feedback, adopted a new approach to preview features in the production Kubernetes environment, enhancing their product development process.
Previous articles in this series have discussed the process of moving from local testing, to testing on Kubernetes. This next piece covers two very large teams and how they both set up a shared testing space and handled the inevitable conflicts over who could test when. The result was faster feedback and drastically improved developer velocity. Today we’ll be talking about Uber and DoorDash, two household names that needed ambitious solutions to improve the developer experience.
As a large team Uber has implemented testing at every level. But un-reliable E2E tests were slowing down their process, and earlier stages of testing weren’t a realistic environment for finding problems.
Uber operates thousands of services to power up the platform that drives the company at scale. New updates need to meet all functional requirements before going to Production. Building confidence in meeting functional requirements can be achieved by testing a service.
It is important to test a service in isolation, such as through unit, integration, and component tests, as it provides developers with faster feedback. However, to validate whether the requirements for a service are met with the current state of dependencies and gain confidence, developers rely on end-to-end (E2E) testing.
Services have different deployment pipelines and timings. Some include staging deployment, but not all. This means that dependencies in staging environments may not be as updated as in production. As a result, E2E testing in staging environments can be unreliable.
One issue that comes up again and again when discussing a ‘better’ system for testing on staging, is how a reliance on testing at this level leads to conflict between teams. Everyone wants to use staging at once, and it’s often the first time that most bugs will appear. In a related blog post I talk about existing ways to solve this conflict, and how teams like ShareChat use Signadot to let everyone test on staging at the same time.
In their blog post, the Uber team describes their experience of these conflicts
Staging environment also limits how many developers can test at once. Every developer might have different changes to be tested. They have to claim the staging environments of not only their service, but also of dependencies, which might not be feasible.
The Uber team created a shared staging environment, and implemented a tool to let engineers create on-demand, ephemeral testing environments called Short-Lived Application Testing Environment (SLATE)
During testing, the system under test (SUT) uses production instances of dependencies from the baseline layer, either from staging or production, and deploys those systems under test to production. SUT can also use isolated resources like databases and work queues per service. SLATE has multiple environments, allowing for multiple services to be deployed from git-branches or git-refs.
The system has the benefit of automatically scaling down, so we’re not running resources we don’t need. Each service can be redeployed multiple times, but only the most recent version is kept. Each SLATE environment has a default TTL of 2 days, after which all service deployments are terminated and resources are freed up.
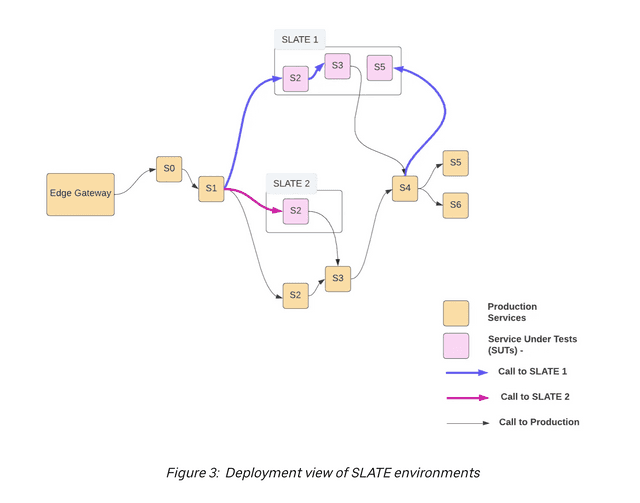
Uber’s SLATE allows for multiple systems to be experimented upon at once. In this example there are three running versions of Service 2!
In Uber, developers primarily use production and staging as runtime environments. This ensures that the environment is as close to the real-life scenario as possible. SLATE is essentially an isolation created inside a production environment, where test instances of services (SUT) can be deployed. With SLATE, developers can conduct various tests, such as performance tests, in a controlled environment, ensuring that the services function optimally before being deployed in the actual production environment. The runtime environment of a SUT is always production, which means that a SUT will operate in a similar environment as the actual service.
Results: Better isolation and improved velocity.
The success of Uber’s SLATE tooling for single-use environments is best summarized from the team’s own writing
SLATE significantly improved the experience and velocity of E2E testing for developers. It allowed them to test their changes spread across multiple services and against production dependencies. Multiple clients like mobile, test-suites, and scripts can be used for testing services deployed in SLATE. A SLATE environment can be created on demand and can be reclaimed when not in reuse, resulting in efficient uses of infrastructure. While providing all this, it enforces data isolation and compliance requirements.
As DoorDash continues to experience rapid growth, the pressure is on for product development to keep up the pace and move new features into production faster and with higher reliability. Shipping features without previewing them in the production Kubernetes environment is a risky proposition that could slow down the entire product development process. If any bugs or defects are discovered, they would require starting from scratch and could be a significant setback.
In a Kubernetes environment, developers must build, push, and container images in the cluster to preview their features before they are pushed to production. However, this previewing process can be slow, especially for a fast-paced organization like DoorDash. This velocity was the key concern for the development productivity team. While inaccurate tests were a concern, the bigger issue was how failed tests and rollbacks hurt velocity. The development productivity team recognized this challenge and had to find a way to build a faster feedback loop to keep up with the company’s growth.
DoorDash’s journey started with a recognition that a shared Kubernetes cluster was the place developers should be experimenting, and their recent blog post (and this piece) explores their journey in how exactly to implement this process
The DoorDash team initially relied on Kubernetes port-forward to create a fast feedback loop, but quickly hit limitations that made this solution unreliable, hard to maintain, and no longer compatible when DoorDash moved to a multi-cluster architecture.
Kubernetes port-forward allows developers to access an application running in a cluster from their workstation. When the port-forward command is executed, requests sent to a local port are forwarded to a port inside a Kubernetes pod. This enables a locally running service to connect to its upstream dependencies, facilitating faster testing without building, pushing docker images, or deploying them in the Kubernetes cluster.
However, Kubernetes port-forward is not a safe or reliable option for product development because:
A common thread here was that DoorDash wanted to test with a near-to-production architecture and production data, without revealing sensitive data to the Dev/Staging environment. This may not be everyone’s requirement, but with DoorDash it makes a ton of sense: when you think about some of the strange menu options and drop-downs in real restaurant’s menus, you’ll know that the real production data will have creative use of object notation that would be very hard to simulate.
While other solutions such as kubefwd address some of these issues, they don’t provide the security features needed for safe product development in a production environment.
The DoorDash developer productivity team considered Telepresence, which provides a fast feedback loop. However the team ended up not selecting Telepresence for two main reasons
💡 While the next section describes the use of Signadot, this should not imply that Signadot is a ‘better’ tool than Telepresence. The fact is that any tool for testing on k8s will have strengths and weaknesses. Signadot is one of many possible tools that you should have in your toolbox when you set out to test on k8s.
From the sections above there were some clear needs for the Doordash team:
Several teams of a similar size to DoorDash have opted for DIY tooling to solve this problem. Teams like Razorpay are devoting teams to maintaining an intelligently routed solution for cluster-based testing of locally hosted code.
In DoorDash’s case, the majority of their needs were covered by Signadot. Doordash leveraged Signadot’s connect feature to connect locally running services to those running in the Kubernetes cluster without changing any configuration. Signadot also supports receiving incoming requests from the cluster to the locally running services.
At the same time, the Doordash team also explored a path for better testing of their releases after the development stage:
Releasing new code carries risk and associated costs that can be mitigated using a gradual rollout strategy. However, Kubernetes does not provide this capability out of the box. All the existing solutions require some form of traffic management strategy, which involves significant changes at the infrastructure level and an engineering effort that can last multiple quarters.
Multi-cluster functionality was a key piece of the solution for DoorDash. Signadot’s CLI was able to fetch service endpoint route information to let this function seamlessly from a developer workstation. Signadot leverages OpenTelemetry to add baggage to every request, and the Signadot router can periodically update it’s list to resolve IP’s in other clusters.
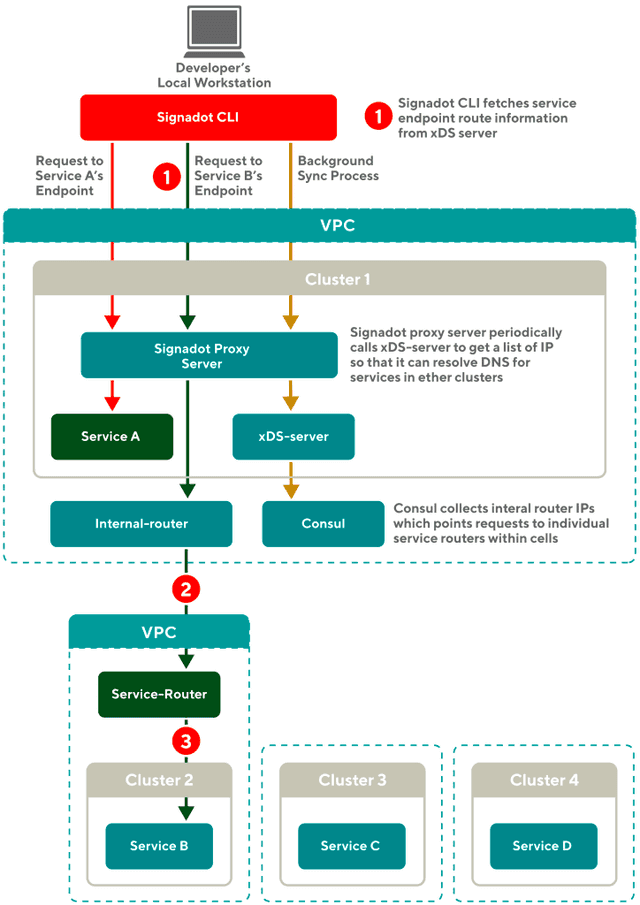
From the DoorDash blog, how requests are routed between the service running on the developer’s laptop.
When a request comes to the internal router, the router routes it to the service router, which then forwards the request to the target cluster. The service router is responsible for routing requests to the appropriate service. Once the target service is identified, the request is forwarded.
In order to facilitate this process, the Signadot proxy server periodically pulls the IP lists for all services from the xDS-server endpoint. The server then updates its own IP list with the current list of available services. When a developer runs the Signadot CLI on their local machine, the CLI pulls the IP lists from the Signadot proxy server and stores one IP for each service in the local /etc/hosts file. This allows developers to easily access and send requests to any service across multiple clusters directly from their local workstations.
This design not only simplifies the process of accessing services, but also helps to reduce the load on the internal DNS server; enabling developers to send requests to any service without overwhelming the internal DNS server with local requests.
This article discusses how large teams at Uber and DoorDash implement testing on Kubernetes. Uber created a way to preview code within the production environment and implemented a tool called Short-Lived Application Testing Environment (SLATE) to let engineers create on-demand, ephemeral testing environments. DoorDash leveraged Signadot’s connect feature to connect locally running services to those running in the Kubernetes cluster without changing any configuration. Signadot also supports receiving incoming requests from the cluster to the locally running services. Both solutions relied on dynamic routing of requests based on headers to isolate developers. Uber’s solution ran the Systems under test in Kubernetes, whereas at DoorDash the services being worked on are running on dev workstations.
Both solutions resulted in faster feedback and improved developer velocity.
Get the latest updates from Signadot

