Discover how Signadot enables the creation of sandboxes in Kubernetes at scale. This blog post explains how Signadot's approach provides lightweight, isolated environments for efficient end-to-end testing, addressing the challenges of scaling microservices development and testing in Kubernetes.
As organizations rapidly grow their development environments, it’s understood that testing should shift left. However, approaching end-to-end and integration testing in Kubernetes and multi-cloud environments still remains a question.
In this post, I will explore a new approach to creating high-fidelity environments for scaling microservices development and testing using Kubernetes. I will also examine some considerations for implementing a lightweight environment solution based on microservices.
When organizations have an architecture with 20+ microservices, there’s a greater need for high-fidelity environments that emulate production. Adding cloud databases and third-party APIs further breaks conventional methods. Many times, growing organizations choose to restrict testing to pre-production environments that simulate production.
Deploying an entire namespace or cluster to encompass all services, particularly at scale, comes with its limitations. As the number of microservices, development teams, and environments grows, infrastructure and operational expenses increase exponentially.
Another challenge with environments presents itself when multiple versions of services and APIs run concurrently in each environment. Although you could test against a single environment, the test outcomes may be different to production because someone might have committed changes to one of the microservices that you were using as a dependency.
Innovative approaches to mitigate this issue involve time-sharing the pre-production environment, wherein a single team employs the staging environment at any given time. However, such workarounds frequently result in significant expenses and cause bottlenecks that slow down development.
A sandbox is a lightweight environment that combines the test versions of one or more microservices with a common set of services representing the most recent stable versions of microservice dependencies. The underlying concept is to have a shared pool of dependencies that is regularly updated with stable versions from the main branch. When you make changes, only those changes are deployed into a clean baseline environment such as staging or production.
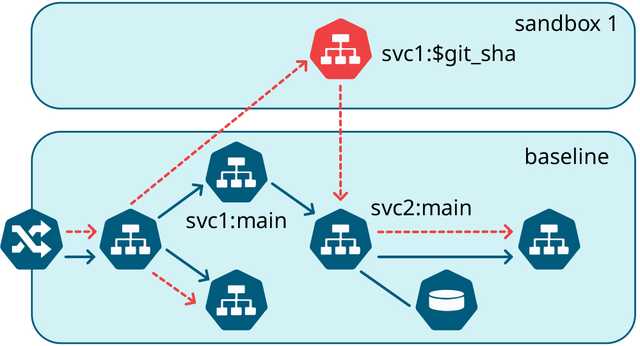
The image above depicts a standard microservice stack present in the baseline environment. A sandbox can take the form of a branch or a pull request that carries a test version of a service. In the image, the orange path illustrates the journey of a request. At this point, you can reroute the request to follow the orange path instead of the original blue path. This process can be repeated multiple times using different sets of microservices, resulting in distinct test environments because each request flow is executed in isolation.
The next question that arises is how to create a sandbox in Kubernetes. To answer this, we must first consider several critical aspects and design choices, starting with how we define and deploy workloads. In the image above, we observe one or more sandboxed services being deployed. A workload can be deployed as part of the CI/CD process, or an alternative approach involves deriving the Kubernetes workload from the baseline. One way to achieve a test version is to upload the complete YAML specification of the service to the cluster and store it somewhere, or standardize the baseline deployment.
Based on our experience, most sandboxed workloads only have a few modifications. It’s rare for a sandboxed workload to have a configuration that differs entirely from the baseline in every aspect.
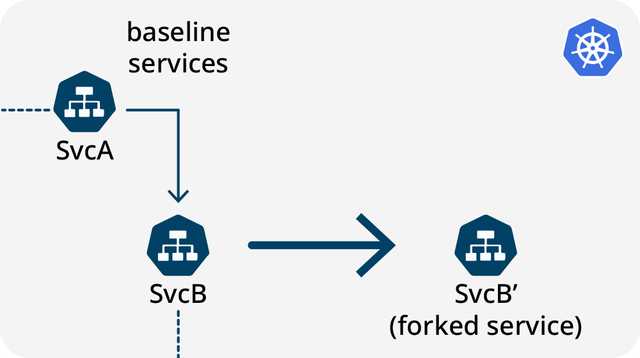
The format we chose in our implementation was to specify the customization in terms of “forks”. To customize a runtime deployment in Kubernetes, all you need to do is indicate the “fork” and reference it, followed by specifying the modifications. The changes are the only customization made.
One major advantage of a test version derived from the baseline is that any changes to the baseline are automatically reflected in the test version of the workload.
Another aspect of the equation concerns stateful resources. Certain resources such as databases and message queues may require extra isolation. As it may not be feasible to isolate them at the request level, you might need to deploy these ephemeral stateful resources alongside the sandbox.
For example, consider a sandbox containing one Kubernetes workload. You can deploy additional resources and associate them with the sandbox, such as a message queue that requires communication or a database that has already been populated with some data. The purpose is to link each resource to the lifecycle in a way that ensures that the resource is clean when the sandbox is terminated.
It’s also important to consider whether infrastructure-level isolation is necessary. In traditional environments, isolation is applied at the infrastructure level. However, in this scenario, you have the option to choose. If the data store or the message queue provides some form of tenancy, logical isolation is preferable since it is a more lightweight mechanism. (For example, it would be akin to linking a Kafka topic with a sandbox instead of an entire Kafka cluster.)
To maintain a self-contained sandbox, you must determine the level of isolation you prefer and incorporate the necessary resources accordingly. You must also provide these credentials to your workloads to enable them to interconnect. Ultimately, the objective is to ensure that the sandbox remains self-contained.
Request routing determines which flow it actually belongs to. The image below demonstrates how the routing key k1 must persist all the way through the chain to facilitate local routing decisions, enabling requests to be directed to the test workload instead of the baseline workload.
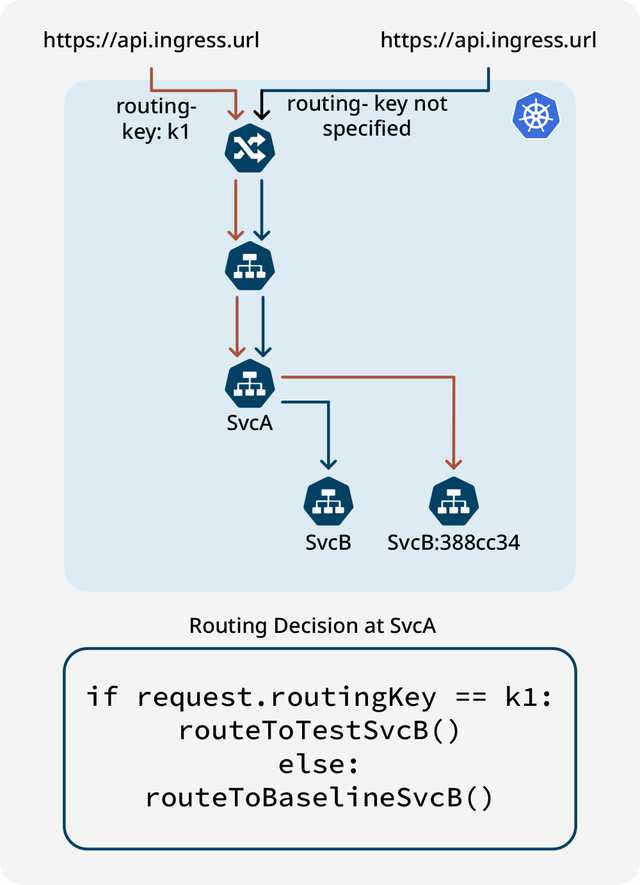
The easiest way to achieve this objective is by utilizing request headers, which can be conveniently implemented with the help of projects like OpenTelemetry. The W3C standard offers tracestate and baggage headers, which are well-supported in OpenTelemetry. Several programming languages allow the easy addition of the library to employ request headers with minimal effort. However, in some cases, it may be necessary to retrieve the request on the incoming side and then transmit the routing key or context to the outgoing side.
In this instance, the implementation would employ some tracing primitives, but the tracing backend itself would be unnecessary. The only thing that’s needed is for every request coming into the service to persist routing key k1 as it passes the request along to the next service in the chain. In certain instances, when communicating with an external service like Pub/Sub, the service may not support headers. In such a scenario, a query parameter would be utilized to maintain context all the way through the chain.
The final aspect to consider is how the actual routing occurs, which is a more local decision. When dealing with every service, you’ll need to decide whether to redirect the request to a test workload or transmit it to the baseline. Various approaches exist, each with its own advantages and drawbacks. The most straightforward approach involves using a Sidecar, where a container operates alongside the primary workload, dealing with aspects such as network policy. Integrating a Sidecar container can help intercept the request and make the routing decision. Another approach involves using Istio or a service mesh that can be trained to route such requests.
For performance-sensitive development efforts, L7 protocol interceptors (such as HTTP and gRPC) offer an alternative for making routing decisions in the application layer itself. However, if a service mesh is absent, implementing the Sidecar container route is likely the most straightforward choice.
First, sandboxes enable you to modify the backend at any point in the stack and test the change from the frontend, ensuring that the feature performs as intended before merging code. Consequently, you can have complete faith in the feature’s functionality before merging code.
Second, multiple sandboxes can work together. While testing a new feature that spans across different microservices, it can be merged into a single routing context, allowing requests to pass through both of them. This is an effective approach for conducting cross-service testing before moving to a shared staging environment.
Third, because sandboxes are lightweight, they can usually spin up in under 30 seconds. This makes it possible to perform testing at scale while keeping costs in check. By quickly deploying a lightweight environment, developers can efficiently perform testing on real environments. Employing this approach significantly accelerates the development process without incurring excessive expenses.
So where does Signadot fit into all of this? Signadot primarily focuses on building lightweight environments and making them available on Kubernetes. Signadot has an implementation of the Sandboxes paradigm. Using a Kubernetes operator, there is a simple interface to define and deploy sandboxed workloads and configure routing rules for them. An extensible resource plugin framework is used to specify which ephemeral resources should be spun up as part of the sandbox. In addition, sandboxes allow for a seamless experience when using APIs, SDKs, and other integration layers.
Sandboxes enable you to:
The idea behind sandboxes is to allow teams to create multiple instances within a single Kubernetes cluster without incurring the cost and operational complexity of replicating physical environments. Uber , Lyft, and DoorDash are examples of large corporations that have successfully implemented scalable, testing solutions that leverage the sandbox concept to create environments that require minimal resources and spin up instantly.
To learn more, check out our Documentation or join Signadot’s community Slack channel.
Get the latest updates from Signadot

