Comprehensive Guide to Preview Environment solutions for Kubernetes

Image by Mo from Unsplash.
Introduction: Escaping the Staging Bottleneck
In the landscape of modern software development, particularly within microservice-based architectures, the traditional, monolithic staging environment has evolved from a reliable proving ground into a significant impediment to velocity. This shared, long-lived environment, once a staple of the software development lifecycle (SDLC), now frequently represents a central bottleneck. Teams operating in parallel find themselves in a constant state of resource contention, queuing for their turn to deploy and test features. This queuing behavior directly contradicts the agile principles of rapid, independent deployment that microservices are intended to enable.
A primary challenge of the shared staging environment is the high risk of "feature fratricide," where multiple, concurrent, and often unstable features are deployed into the same space. When a test fails, it becomes a time-consuming forensic exercise to determine whether the failure was caused by one's own changes, a colleague's recent deployment, or a latent issue in the environment itself. This uncertainty erodes developer confidence and slows down the entire delivery pipeline. Furthermore, these environments are susceptible to configuration drift, where their state slowly diverges from production, diminishing the value of the tests performed within them. As application complexity and team size scale, these problems are magnified, transforming the staging environment into a primary constraint on an organization's ability to innovate and release software frequently and reliably.
Defining the Modern Preview Environment
In response to the limitations of traditional staging, a new paradigm has emerged: the modern preview environment. A preview environment is an on-demand, isolated, and ephemeral deployment created automatically for a specific branch or, more commonly, a Pull Request (PR). Unlike their static predecessors, these environments are dynamic components of the development workflow, designed to provide a high-fidelity preview of code changes as they would behave in production. Their lifecycle is intrinsically tied to the PR they serve; they are provisioned when the PR is opened and automatically destroyed upon merge or closure, a practice that ensures a clean slate for every set of changes and conserves valuable infrastructure resources.
The core attributes of a well-architected preview environment system are critical to its success:
- On-Demand & Ephemeral: Environments are created and destroyed automatically, aligning their lifecycle with that of the feature being developed. This temporary nature is a key differentiator, preventing resource waste and eliminating the "leftover" data and configurations that plague static environments.
- Production-Like: To be effective, a preview environment must mirror the production environment as closely as possible. This includes using similar services, dependencies, data schemas, and underlying infrastructure configurations. This fidelity is essential for reliably identifying integration gaps and performance issues early, effectively solving the classic "but it works on my machine" problem by moving validation off the developer's local machine and onto a realistic, shared infrastructure.
- Isolated: Each preview environment is self-contained, ensuring that tests for one PR cannot interfere with the tests for another. This parallelism is crucial for unblocking teams and eliminating the bottlenecks associated with shared staging environments. Isolation can be achieved at various levels—from the Kubernetes namespace to the individual application request—but the goal remains the same: to guarantee that any observed behavior is a direct result of the changes within the PR.
- Automated & GitOps-Driven: The creation, updating, and destruction of preview environments should be fully automated and integrated with the organization's CI/CD pipeline and version control system (VCS), such as Git. This automation, often following GitOps principles, means the environments respond to repository events (e.g., opening a PR, pushing a new commit) without requiring manual intervention, thereby reducing cognitive load on developers and embedding the process seamlessly into their existing workflow.
The Transformative Benefits of PR-Centric Previews
The adoption of PR-centric preview environments yields a host of transformative benefits that ripple across the entire engineering organization, fundamentally altering how teams collaborate, test, and deliver software.
- Accelerated Feedback Loops: Perhaps the most significant advantage is the drastic compression of feedback cycles. In a traditional workflow, critical feedback from stakeholders often arrives late, after code has been merged and deployed to a staging environment. Preview environments shift this feedback to the earliest possible moment—during the PR review process itself. Developers can receive immediate, actionable input from product managers, designers, and QA engineers, allowing for rapid iteration and refinement before the code is ever merged into the main branch. This real-time validation can reduce feature delivery times by as much as 60% by eliminating the dependencies on shared environments.
- Enhanced Collaboration: Preview environments act as a powerful collaboration hub. By providing a unique, shareable URL for each PR, they democratize the review process. Non-technical stakeholders, who would otherwise rely on static mockups or screenshots, can now interact with a live, fully functional version of the feature. Product managers can perform User Acceptance Testing (UAT) , designers can validate the user experience, and marketing teams can align on messaging, all based on the same interactive artifact. This shared context reduces miscommunication and ensures that the final product is a result of holistic, cross-functional input, not just a successful code diff.
- Shift-Left Quality Assurance: The practice of "shifting left" involves moving testing activities earlier in the development lifecycle. Preview environments are a cornerstone of this philosophy. They enable comprehensive testing—including unit, integration, and full end-to-end (E2E) tests—to be executed against a production-like environment for every single PR. This allows for the detection of complex integration bugs and performance regressions that would be nearly impossible to catch in a local development environment or with unit tests alone. By identifying and resolving these issues before a merge, organizations can significantly reduce the number of production bugs, with some reporting up to a 50% decrease.
- Improved Developer Experience (DevEx): For engineering managers focused on optimizing developer productivity, preview environments offer a substantial improvement to DevEx. They eliminate the frustrating wait times and contention associated with shared staging environments, allowing developers to test their work in parallel. They also unburden team leads and senior engineers from the time-consuming task of manually pulling down PR branches to their local machines for validation—a process that is inefficient and lacks standardization. By providing a standardized, automated, and high-fidelity testing environment on demand, preview environments boost developer confidence, reduce infrastructure-related delays, and allow engineers to focus on what they do best: writing and shipping high-quality code.
The move toward preview environments is more than a simple tooling upgrade; it signifies a profound evolution in the software development process. The traditional, linear progression—develop, review, merge, test—is inherently inefficient, creating hand-offs and delays at each stage. The introduction of a preview environment for every PR dissolves this sequential model, replacing it with a highly parallel and collaborative workflow. When a PR is opened, it triggers a convergence of activities: code review by peers, automated testing by the CI system, exploratory testing by QA, and functional review by product and design stakeholders all occur simultaneously. This parallelization not only accelerates the delivery timeline but also fundamentally changes the nature of collaboration, fostering a more integrated and agile culture where quality is a shared responsibility from the very beginning of a feature's lifecycle.
The Full-Duplication Model: Okteto
Core Philosophy: The Ultimate Developer Experience
Okteto's market position and product philosophy are squarely focused on maximizing developer productivity and delivering a superior Developer Experience (DevEx). The platform is engineered to abstract away the inherent complexities of Kubernetes, providing a seamless bridge between local development and a production-like cloud environment. The core tenet is to empower developers to concentrate on application logic and code, rather than becoming experts in infrastructure configuration and management. Okteto aims to replicate the speed and immediacy of local development within a robust, shareable, and high-fidelity cloud-native setting.
Architectural Deep Dive: Namespace-per-PR Replication
The architectural foundation of Okteto's preview environment solution is full-stack replication. For each pull request, Okteto provisions a complete, independent copy of the application stack, including all microservices, databases, and other dependencies.
- Isolation Mechanism: This full replication is achieved by creating a dedicated and isolated Kubernetes namespace for each preview environment. This namespace acts as a hard boundary, ensuring that the resources for one PR (e.g.,
app-pr-123) are completely separate from those of another (e.g., app-pr-124). The okteto namespace create command is a fundamental primitive within the Okteto CLI, underscoring the centrality of this approach. - Configuration: The entire environment—its services, deployment commands, dependencies, and development container settings—is defined declaratively within an okteto.yaml manifest file. This file serves as the single source of truth for what constitutes a development or preview environment, ensuring consistency and repeatability.
- Workflow: The process is tightly integrated with standard CI/CD practices:
- A developer finalizes a feature and opens a pull request in a Git repository.
- This event triggers a CI/CD pipeline (e.g., using GitHub Actions, GitLab CI). The pipeline executes the okteto deploy command, which reads the okteto.yaml manifest.
- Okteto's platform receives the command and orchestrates the creation of a new, uniquely named Kubernetes namespace. It then proceeds to deploy all the components defined in the manifest into this new namespace.
- Upon successful deployment, Okteto generates and reports back a unique, shareable URL that provides access to the running preview environment, which can then be posted as a comment on the PR for easy access by reviewers.
- Inner Loop Optimization: A standout feature of the Okteto platform is its optimization of the "inner loop" development cycle. Using the okteto up command, a developer can establish a real-time, two-way file synchronization between their local filesystem and the development container running in the remote Kubernetes cluster. This allows code changes to be reflected in the running application in seconds, completely bypassing the time-consuming container build-and-push cycle that can take several minutes. This rapid feedback mechanism is a cornerstone of Okteto's DevEx-centric philosophy.
Strengths and Ideal Use Cases
The full-duplication model offers several distinct advantages, particularly for certain types of teams and applications.
- Simplicity and Ease of Use: The mental model for developers is exceptionally straightforward. Each developer receives their own private, complete copy of the application. There is no need to reason about shared state, complex routing rules, or potential interference from other services. This simplicity lowers the barrier to entry and allows developers to be productive quickly without needing deep Kubernetes expertise.
- Complete Isolation: Because every component of the stack is duplicated within a dedicated namespace, the risk of cross-environment interference is effectively zero. This provides a very high degree of confidence that any observed behavior or test result is a direct consequence of the code changes within the pull request. This level of isolation is ideal for sensitive tests or when debugging complex, intermittent issues.
- Excellent Inner-Loop DevEx: The fast file synchronization feature (okteto up) is a significant productivity enhancer for developers during the active coding and debugging phase. The ability to see changes reflected in a production-like environment almost instantly is a powerful capability that dramatically shortens the code-test-debug loop.
Limitations and Challenges
Despite its developer-friendly nature, the namespace-per-PR replication model carries significant challenges that become more pronounced at scale.
- Resource Inefficiency and Cost: This is the primary and most critical drawback. The model's resource consumption and associated infrastructure costs scale linearly with both the number of microservices in the application and the number of active pull requests. For an application with 20 microservices, each open PR will spin up 20 service deployments, plus any associated databases or caches. For a team with 10 active PRs, this translates to 200 running services. This resource explosion can become prohibitively expensive and difficult to manage as teams and applications grow.
- Performance at Scale: The time required to spin up a preview environment is directly proportional to the complexity of the application. For large applications with many services and complex startup dependencies, the provisioning time can extend to several minutes, which begins to erode the benefit of a "rapid" feedback loop.
- Environment Parity and Maintenance: Maintaining dozens or even hundreds of independent, ephemeral environments and ensuring they remain in sync with production becomes a substantial operational challenge. Furthermore, the problem of data seeding—populating each ephemeral database with realistic and useful test data—is a non-trivial task that must be solved for each environment instance, adding to the complexity.
The architectural decisions made by Okteto represent a clear and deliberate trade-off. The platform prioritizes the autonomy and mental ease of the individual developer above all else, choosing a model that provides unambiguous ownership and complete isolation. This approach is the most faithful cloud-native translation of the traditional "development environment on my laptop" concept, where every developer has their own self-contained world. The direct consequence of this architectural choice is the linear scaling of cost and resource usage, a point frequently highlighted in comparative analyses. For every unit of developer isolation—a single PR environment—the platform incurs a full unit of infrastructure cost. This reveals a philosophical stance: the cost of a developer's time and cognitive load is deemed more significant than the cost of the underlying infrastructure. This equation holds true for smaller teams or applications with moderate complexity. However, as an organization's scale and application complexity increase, this balance inverts, making the full-duplication model less tenable and economically unsustainable for large enterprises.
The Virtual Cluster Model: vcluster
Core Philosophy: True Kubernetes Isolation, Virtualized
The core philosophy of vcluster is to deliver the robust isolation and administrative boundaries of separate physical Kubernetes clusters but without the significant financial and operational overhead they entail. It carves out a unique position in the ecosystem by offering an isolation model that is substantially stronger and more secure than standard Kubernetes namespaces, yet far more lightweight, affordable, and faster to provision than dedicated, full-blown clusters. vcluster is designed for multi-tenancy, empowering teams to operate with full autonomy on shared infrastructure.
Architectural Deep Dive: A Cluster Within a Namespace
vcluster's architecture is an elegant implementation of cluster virtualization within Kubernetes itself.
- Core Components: The fundamental principle of vcluster involves running a virtualized Kubernetes control plane as a standard workload within a single namespace of a "host" Kubernetes cluster. This virtual control plane is typically packaged as a StatefulSet and contains its own lightweight API server, a controller manager, and a data store (which defaults to an embedded SQLite database for efficiency). This means each vcluster has its own distinct API endpoint, separate from the host cluster's API.
- The Syncer: The magic of vcluster lies in a critical component called the syncer. When a user or a CI/CD process creates a Kubernetes resource (like a Pod or a Service) by interacting with the vcluster's API server, the resource is recorded in the vcluster's data store. The syncer component, which runs alongside the virtual control plane, detects this new resource. It then creates a corresponding "real" resource in the host cluster's namespace. This real Pod is scheduled onto a physical node by the host cluster's scheduler, but all of its subsequent lifecycle management (updates, deletions) is governed by the virtual control plane it originated from.
- Isolation Mechanism: The isolation provided by vcluster is at the Kubernetes API level, which is a significantly stronger boundary than a simple namespace. Users of a vcluster can be granted cluster-admin privileges within their virtual cluster, allowing them to install operators, manage CRDs, and configure RoleBindings, all without possessing any elevated permissions on the underlying host cluster. This robust security model is a key differentiator, preventing "noisy neighbor" problems where one tenant's actions could disrupt the entire host cluster.
- Workflow for Preview Environments:
- The process begins when a pull request is opened, triggering a CI/CD pipeline (e.g., via GitHub Actions).
- The pipeline script executes commands against the vCluster Platform or uses the open-source vcluster CLI to provision a new virtual cluster. This is typically done using a pre-configured virtual cluster template that defines its characteristics, such as the Kubernetes distribution to use (e.g., K3s, k0s) and any specific configurations. The newly created vcluster and its components reside within a dedicated namespace on the host cluster.
- Once the vcluster is active, the pipeline proceeds to deploy the application's manifests (e.g., using helm install or kubectl apply) directly into the new virtual cluster.
- To expose the preview application to the outside world, Ingress resources created within the vcluster can be automatically synced by the syncer to the host cluster's IngressController. This allows the application to be accessible via a unique URL, just like any other service on the host cluster.
- Upon the closure or merging of the pull request, a corresponding cleanup job in the CI/CD pipeline is triggered. This job destroys the virtual cluster and its associated host namespace, ensuring all resources are reclaimed.
Strengths and Ideal Use Cases
The virtual cluster model provides distinct advantages that make it particularly well-suited for specific, demanding use cases.
- Superior Security and Isolation: This is the primary and most compelling benefit of vcluster. By providing each tenant (or in this case, each preview environment) with its own control plane, it creates a powerful security boundary. This model is ideal for organizations with high security and compliance requirements, as it ensures that actions within one preview environment cannot affect the stability or security of the host cluster or other tenants.
- Testing Cluster-Level Changes: Because each vcluster is a genuine, albeit virtualized, Kubernetes cluster, it is the perfect environment for testing changes that go beyond simple application code. If a pull request involves installing or upgrading a Kubernetes Operator, introducing new Custom Resource Definitions (CRDs), or modifying cluster-wide permissions and network policies, vcluster is the only model (short of provisioning a full physical cluster) that can safely and accurately test these changes in an isolated manner.
- Cost-Effectiveness at Scale (vs. Physical Clusters): When the alternative is provisioning a new physical cloud cluster (e.g., EKS, GKE, AKS) for each preview environment, vcluster offers dramatic cost and time savings. A vcluster can be spun up in seconds, whereas a new cloud-managed Kubernetes cluster can take many minutes to become available. This makes ephemeral, per-PR clusters logistically and financially feasible.
Limitations and Challenges
While powerful, the vcluster approach is not without its own set of trade-offs and complexities.
- Resource Overhead (vs. Shared Models): Although significantly lighter than a full physical cluster, a vcluster still incurs more resource overhead than models that share a control plane, such as namespace-based or request-based isolation. Each vcluster runs its own API server and controller manager, which consume CPU and memory resources on the host cluster.
- Configuration Complexity: The initial setup and ongoing management of vcluster templates can be more complex than simpler models. Configuring the interaction between the virtual cluster and the host cluster, such as syncing ingresses, sharing services, or defining specific network policies, requires a deeper understanding of both vcluster's configuration and Kubernetes networking.
- Potential Overkill for Simple Changes: For a routine pull request that only involves updating a single service's container image, the overhead of creating and managing an entire virtual Kubernetes cluster might be unnecessary. In such cases, a more lightweight approach could be more efficient.
The positioning of vcluster in the market and its architectural design reveal its fundamental nature as a platform-building and multi-tenancy tool that has found an excellent secondary application in the realm of preview environments. Its core value proposition is not just the isolation of application workloads, but the isolation of the Kubernetes control plane itself. This is evident from its documentation and features, which consistently highlight use cases like providing "self-service Kubernetes for developers" or enabling ISVs to "host each customer in a virtual cluster". When this capability is applied to preview environments, its unique strength becomes clear: it excels in scenarios where a pull request contains changes that transcend the application layer. If a PR modifies an operator, introduces a new CRD, or requires specific cluster configurations that could conflict with other tenants, vcluster provides the necessary sandbox to test these changes safely. This implies that vcluster is the optimal choice for organizations with advanced Kubernetes usage, high security postures, or those building complex platforms where application development is tightly coupled with changes to the underlying cluster infrastructure. It solves a deeper, more structural isolation problem than simple workload-duplication models.
The GitOps-Native Model: ArgoCD and Jenkins
Core Philosophy: Declarative, Auditable, and Extensible
The approach of using a combination of a CI tool like Jenkins and a GitOps CD tool like ArgoCD is fundamentally rooted in the core principles of GitOps. This philosophy posits that Git should serve as the single source of truth for the desired state of not only the application code but also its operational environment. Every action, from the initial deployment of a preview environment to its eventual teardown, is managed through declarative manifests stored in a Git repository. This ensures that the entire process is automated, auditable, and transparent, leaving a clear, version-controlled history of every change made to every environment. This model prioritizes flexibility, control, and governance above all else.
Architectural Deep Dive: The Two-Repository CI/CD Flow
Implementing preview environments with this model typically relies on a well-defined workflow that spans two distinct Git repositories: one for the application source code and a separate one for the Kubernetes deployment manifests, often referred to as the "GitOps repository". This separation of concerns is a widely adopted best practice in the GitOps community.
The Role of the CI Tool (Jenkins): The process is initiated within the Continuous Integration pipeline.
- A developer pushes code to a feature branch and opens a pull request in the application source code repository.
- This event triggers a Jenkins pipeline. The pipeline's first responsibilities are to build the application's container image, run unit and integration tests, and tag the resulting image with a unique identifier, such as the Git commit SHA or the PR number.
- The critical and most complex step follows: the Jenkins pipeline script checks out the GitOps repository. It then programmatically modifies the Kubernetes manifests within this repository. This could involve using a tool like kustomize or sed to update the image tag in a deployment.yaml file to point to the newly built image. Finally, the Jenkins pipeline commits these changes to a new branch in the GitOps repository and automatically opens a new, paired pull request.
The Role of the CD Tool (ArgoCD): The Continuous Deployment part of the workflow is managed by ArgoCD.
- A special ArgoCD resource, the ApplicationSet, is configured to monitor the GitOps repository. This ApplicationSet is equipped with a Pull Request Generator, a powerful feature that can automatically discover open PRs in a specified GitHub, GitLab, or Bitbucket repository.
- When the generator detects the new pull request created by the Jenkins pipeline, it uses a predefined template to dynamically generate an ArgoCD Application custom resource.
- This dynamically generated Application resource is configured with parameters extracted from the pull request. For instance, it points to the specific PR branch in the GitOps repo as its source of manifests and is configured to deploy the application into a new, unique Kubernetes namespace, often named dynamically using the PR number or branch name (e.g., my-app-pr-123). ArgoCD's
syncOptions can be set to CreateNamespace=true to handle this automatically. - ArgoCD's reconciliation loop then takes over, comparing the desired state in the GitOps PR branch with the actual state in the cluster and applying the necessary changes to deploy the preview environment.
- The lifecycle is completed when the pull request in the GitOps repository is closed or merged. The ApplicationSet generator detects this event and automatically deletes the corresponding Application resource. With a prune: true policy, ArgoCD then removes all associated Kubernetes resources, effectively tearing down the ephemeral environment.
Strengths and Ideal Use Cases
This "build-it-yourself" approach offers a unique set of advantages for organizations with the right capabilities and requirements.
- Maximum Flexibility and Control: Because the entire workflow is constructed from powerful, general-purpose, and highly extensible open-source tools, the organization has complete control to customize every single aspect. The logic in the Jenkins pipeline and the configuration of the ArgoCD ApplicationSet can be tailored to fit any specific or esoteric requirement.
- Strong Auditability and Governance: The GitOps methodology ensures that every change to every environment, no matter how small, is represented as a commit in a Git repository. This provides an immutable, chronological, and perfectly auditable history of the state of all environments, which is a critical requirement for organizations in highly regulated industries like finance or healthcare.
- Vendor-Agnostic and Open-Source: This approach avoids lock-in to any proprietary commercial platform. It is built entirely on well-supported open-source projects with large communities, giving the organization full ownership of its tooling stack.
Limitations and Challenges
The power and flexibility of this model come at a significant cost in terms of complexity and effort.
- High Implementation Complexity: This is not an out-of-the-box solution but a significant internal software engineering project. It requires deep, cross-functional expertise in Jenkins pipeline scripting (e.g., Groovy), advanced ArgoCD concepts (ApplicationSet generators), Kubernetes manifest management (Helm, Kustomize), and general automation scripting. Setting up the two-repo dance, the pipeline logic, and the generator templates is a non-trivial undertaking.
- Maintenance Overhead: The platform engineering team that builds this custom system is also responsible for its ongoing maintenance, troubleshooting, and evolution. This includes managing Jenkins stability, updating ArgoCD, securing the pipelines, and adapting the system as new requirements emerge.
- "People Process" and Collaboration Hurdles: The automation can introduce new human process challenges. As noted in one analysis, testing features from two different PRs together now requires developers to coordinate the creation and merging of their respective infrastructure PRs, which can be cumbersome.
- Complex Cleanup and Secrets Management: While ArgoCD can prune the resources it knows about, ensuring a comprehensive cleanup of all associated artifacts (e.g., dynamically created databases, storage buckets, DNS records) requires custom logic to be built into the pipeline. Similarly, securely injecting secrets into dozens of dynamically created ephemeral environments is a complex security challenge that the team must solve from the ground up.
The choice to implement preview environments using the ArgoCD and Jenkins model is a clear embodiment of the "build" side of the classic "build vs. buy" dilemma for internal platform tooling. It consciously trades the convenience, polished user experience, and managed support of a commercial product for ultimate power, control, and customizability. The documented workflows are not simple tutorials but complex recipes demanding a high degree of DevOps maturity. The challenges that must be overcome—such as comprehensive cleanup, secrets management, and user-friendly collaboration flows—are precisely the problems that dedicated commercial tools are designed to solve out of the box. Therefore, embarking on this path is a strategic decision to invest significant and ongoing engineering resources into building a bespoke internal developer platform. This is a feasible and often desirable path for large organizations that possess a dedicated platform engineering function and have a strategic imperative to own and tailor their core developer tooling to their unique operational and governance needs.
The Request-Level Isolation Model: Signadot
Core Philosophy: Share More, Copy Less
Signadot introduces a paradigm that is a radical departure from the conventional wisdom of environment duplication. Its foundational principle is to "share more, copy less," achieving robust isolation not by cloning infrastructure, but by intelligently routing individual application requests. The platform is engineered to provide preview environments that are exceptionally fast to create, highly cost-efficient, and immensely scalable. This approach is specifically designed to address the challenges of testing in complex microservice architectures, where duplicating the entire stack for every pull request is logistically impractical and financially prohibitive.
Unique Architectural Deep Dive: Sandboxes, Service Forking, and Dynamic Routing
Signadot's unique architecture is built upon three core concepts that work in concert to deliver on its philosophy.
Baseline Environment: The system operates on the concept of a single, shared, long-lived "baseline" environment. This is typically an existing staging or QA Kubernetes cluster that is maintained in a state that closely mirrors production. This baseline serves as the stable foundation against which all changes are tested.
Sandboxes and Service Forking:
- When a developer requires a preview environment for their pull request, they do not clone the entire baseline. Instead, they create a logical, lightweight entity called a "Sandbox".
- A Sandbox definition specifies which services are being modified in the PR. For each of these services, the Signadot Operator—a controller running within the Kubernetes cluster—creates a "forked workload".
- This forked workload is a new Kubernetes Deployment of the modified service, running the new container image from the PR. Critically, all other unmodified services, databases, and dependencies within the baseline environment are shared, not copied. This "forking" action is the key to the model's resource efficiency.
Dynamic Request Routing: This is the technological heart of the Signadot model, enabling isolation on shared infrastructure.
- To access a specific preview, a user or an automated test initiates a request with a special context. This context is typically carried in an HTTP header, such as baggage: sd-routing-key=<sandbox-id>. This header can be added manually with tools like curl, or more conveniently, injected automatically by the Signadot browser extension.
- The Signadot Operator, running in the cluster, is responsible for intercepting network traffic between services. It can achieve this using its own lightweight DevMesh (which injects a sidecar proxy) or by integrating with and controlling an existing service mesh like Istio or Linkerd.
- The Operator's proxy inspects the header of each incoming request. If it detects a sd-routing-key that corresponds to an active Sandbox, it dynamically routes the request to the appropriate forked workload for that service.
- If a request arrives without a sd-routing-key header, it is treated as normal traffic and is routed to the stable baseline service.
- Most importantly, this routing context is propagated throughout the entire downstream call chain of the microservices application. When the forked service calls another service, the proxy ensures the sd-routing-key header is passed along. This ensures that the entire end-to-end request remains within the logical boundary of the Sandbox, creating a virtual "slice" of the application for that specific test, even though the underlying infrastructure is shared.
Transformative Benefits and Strengths
This innovative architecture yields a set of powerful benefits that directly address the primary pain points of other models.
- Unmatched Resource Efficiency and Cost Savings: This is the most profound advantage. Since only the services being actively changed are deployed, the marginal resource overhead per preview environment is minimal. This results in dramatic infrastructure cost savings, with claims of 85-90% reductions compared to full-duplication models. For an organization with hundreds of microservices, this difference translates into millions of dollars in annual savings.
- Blazing-Fast Environment Creation: Sandboxes can be spun up in seconds. The system does not need to wait for dozens of services, databases, or other infrastructure to be provisioned and become ready. This provides developers with a near-instantaneous feedback loop, allowing them to preview their changes almost as soon as they push their code.
- High-Fidelity Testing: Developers are able to test their changes against the actual shared dependencies—the same databases, message queues, and third-party APIs that the baseline environment uses. This is a significant step up in fidelity from testing against fresh, ephemeral, and often empty copies of these dependencies. It dramatically increases the likelihood of catching subtle, real-world integration issues that only manifest when interacting with long-running, stateful systems.
- Exceptional Scalability: The request-level isolation model scales effortlessly. Because the marginal cost of each additional Sandbox is so low, the system can support hundreds of concurrent preview environments on a single baseline cluster without performance degradation or resource exhaustion. This is a critical capability for large engineering organizations.
- Advanced Cross-Team Collaboration: Signadot allows multiple independent Sandboxes to be logically grouped together into "Route Groups." This powerful feature enables developers from different teams to easily test the integration of their respective in-progress features together before any code is merged, solving a common and difficult collaboration challenge in microservice development.
Limitations and Considerations
The power of Signadot's model is predicated on certain architectural patterns and carries its own set of considerations.
- Context Propagation Requirement: The model's reliance on dynamic routing requires that the application's services are instrumented to correctly propagate the routing context (i.e., the HTTP headers) from one service to the next. While this is a widely accepted best practice in modern microservice design and is natively supported by instrumentation frameworks like OpenTelemetry, it can pose an adoption barrier for legacy applications or those not built with this capability in mind.
- Stateful Service Complexity: Testing changes that involve destructive database schema migrations or other stateful modifications requires careful planning in a shared-database model. While Signadot provides patterns to handle this, such as spinning up an ephemeral database as a "Resource" within the Sandbox for the duration of the test, it is a more complex scenario than a simple stateless service change and must be designed for explicitly.
- Asynchronous Workflows: Testing event-driven architectures that use message queues like Kafka or Google Pub/Sub is inherently more complex than synchronous request-response flows. It requires a more sophisticated pattern known as "selective consumption," where consumer services within a Sandbox are configured to only process messages that contain the correct routing context in their metadata. Signadot supports this advanced use case, but it requires specific instrumentation in the message producers and consumers.
The architectural model pioneered by Signadot represents a genuine paradigm shift in pre-production testing. It moves the concept of isolation away from the infrastructure layer (copying compute, storage, and networking) and up to the application layer (slicing a shared system using request context). This is a fundamentally more resource-efficient and cloud-native approach that effectively decouples the cost and complexity of testing from the overall size and complexity of the application. The cost of a preview environment is no longer proportional to the total number of microservices in the system (N), but rather to the number of changed microservices in a given pull request (M), where M is almost always a small fraction of N. This economic and logistical reality makes Signadot's model uniquely capable of supporting true, independent, high-velocity microservice development at a scale where full-duplication models would inevitably collapse under their own weight and cost. It is an enabling technology for large engineering organizations seeking to test every single change thoroughly without breaking their infrastructure budget.
Comparative Analysis and Strategic Framework
The selection of a preview environment tool is not merely a technical choice but a strategic one that reflects an organization's scale, architecture, security posture, and DevOps maturity. The four approaches analyzed—Okteto, vcluster, ArgoCD+Jenkins, and Signadot—represent distinct philosophies on how to solve the problem of pre-production testing. A direct comparison of their underlying architectures and the resulting trade-offs provides a clear framework for decision-making.
The Spectrum of Isolation: A Head-to-Head Comparison
The most critical differentiator among these tools is their chosen method of isolation. This architectural decision dictates nearly every other characteristic of the solution, from cost and speed to fidelity and complexity. Understanding this spectrum is paramount for any technical evaluation.
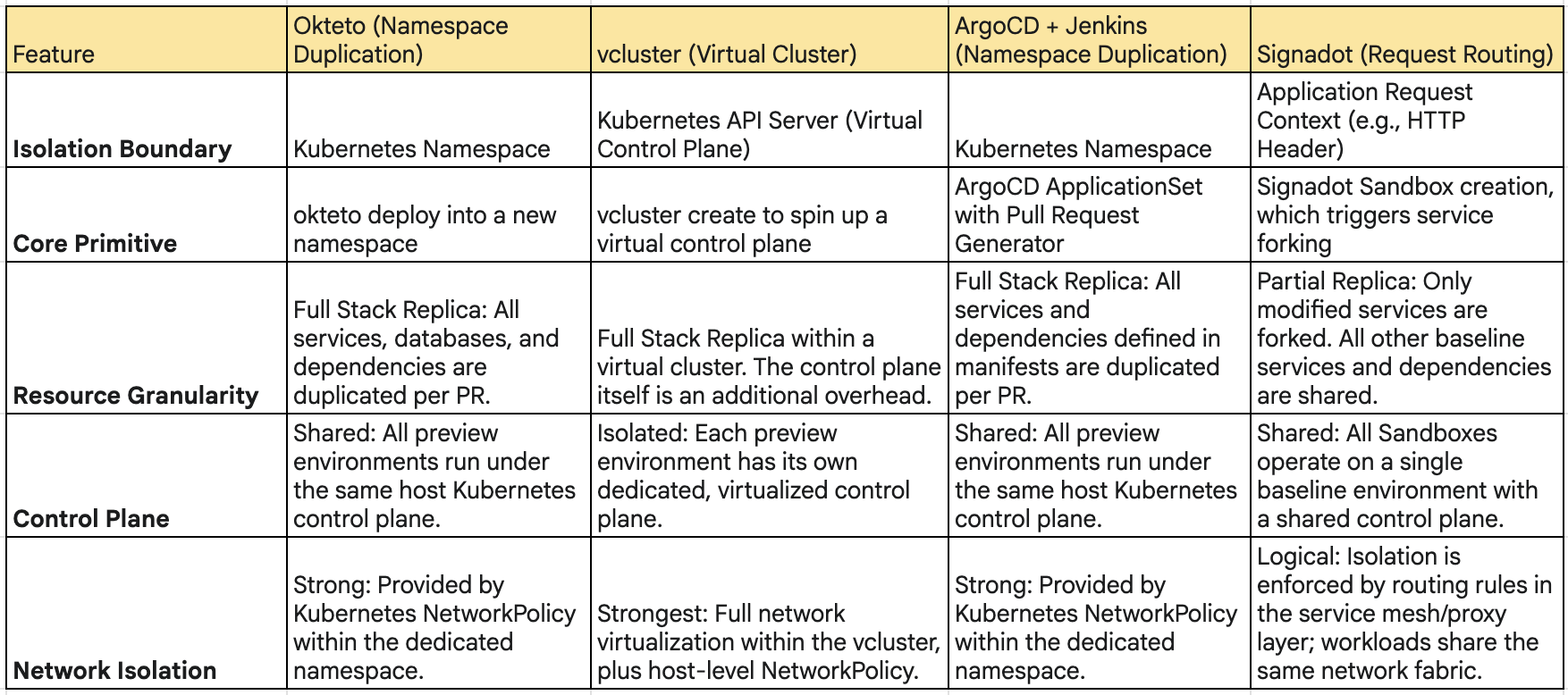
This architectural comparison reveals a clear progression. The Okteto and ArgoCD models provide workload isolation at the namespace level. vcluster elevates this to provide control plane isolation, creating a much stronger security and administrative boundary. Signadot takes a completely different axis, providing logical isolation at the request level, which allows it to forgo infrastructure duplication almost entirely.
Decision Vector Analysis
Moving beyond the core architecture, a comparison across key business and technical vectors helps to contextualize the trade-offs for different organizational priorities.
Resource Efficiency & Total Cost of Ownership (TCO):
- Okteto / ArgoCD: These models exhibit linear cost scaling. The total cost is a function of the number of services multiplied by the number of active PRs (Cost∝N×P). This results in the highest TCO at scale and can quickly become financially unsustainable.
- vcluster: This model has a sub-linear cost profile. It is significantly cheaper than provisioning physical clusters but still incurs a fixed resource overhead for each virtual control plane per PR. Its TCO is lower than full duplication but higher than shared models.
- Signadot: This model offers a near-constant, low-cost profile. The cost scales only with the number of changed services, not the total number of services (Cost∝M×P, where M≪N). This results in the lowest TCO, especially for complex applications, making it the most economically efficient model at scale.
Developer Experience (DevEx) & Speed:
- Okteto: Offers an excellent inner-loop DevEx with its rapid code synchronization feature. However, the initial environment spin-up time can be slow for complex applications, creating a delay before the preview is available.
- Signadot: Delivers the fastest environment creation time, with Sandboxes spinning up in seconds. This provides a near-instantaneous feedback loop from code push to a shareable preview URL.
- vcluster: vcluster creation itself is very fast (seconds), but the overall time to a ready preview environment depends on the application deployment time within the vcluster.
- ArgoCD + Jenkins: This model generally has the slowest feedback loop. The multi-step process (CI build, push image, open infrastructure PR, ArgoCD detection, sync) introduces multiple points of latency.
Scalability & Performance:
- Okteto / ArgoCD: These models scale poorly. As the number of namespaces and pods in the cluster explodes, it can lead to performance degradation of the Kubernetes control plane and scheduler, and significant resource fragmentation.
- vcluster: This model scales well, as it is explicitly designed for multi-tenancy. It effectively partitions the API load, distributing it across the virtual control planes.
- Signadot: Exhibits excellent scalability. The architecture is designed to support hundreds of concurrent Sandboxes on a single baseline cluster with minimal performance impact, as the resource footprint of each preview is very small.
Operational Complexity & Implementation Effort:
- ArgoCD + Jenkins: Highest complexity. This is a full-fledged DIY engineering project requiring significant, ongoing investment in building and maintaining the custom automation.
- vcluster: Medium complexity. It requires the setup and management of vcluster templates, host cluster ingress controllers, and potentially complex networking rules for communication between the host and virtual clusters.
- Signadot: Low complexity. The control plane is managed by Signadot. The implementation requires installing an operator in the cluster and instrumenting applications for context propagation, which is a one-time effort per service.
- Okteto: Lowest complexity. As a fully managed platform, it offers the most straightforward, out-of-the-box setup experience.
Test Fidelity & Reliability:
- Signadot: Offers the highest fidelity. Tests are executed against a stable, shared, production-like baseline environment, including real, long-running stateful services like databases and message queues. This provides the most realistic assessment of how a change will behave in production.
- Okteto / ArgoCD / vcluster: Provide high fidelity in terms of the application code and its direct dependencies being deployed together. However, stateful dependencies like databases are typically fresh, ephemeral copies for each PR. This approach may miss subtle bugs related to data state, schema evolution, or interactions with other long-running services. The challenge of seeding these ephemeral databases with realistic data is significant and often overlooked.
The analysis of these decision vectors reveals that there is no universally "best" tool. Instead, there is a "right" tool for a given set of organizational circumstances. The choice is a strategic one that involves weighing the trade-offs between developer autonomy, cost, security, and implementation effort. A small startup with a simple application and a focus on rapid iteration has vastly different needs and constraints than a large, regulated enterprise with a complex, 200-service mesh and a dedicated platform engineering team. The optimal choice depends entirely on which of these vectors the organization prioritizes most.
Summary and Strategic Recommendations
The transition from static staging environments to dynamic, on-demand preview environments is a critical step in modernizing the software delivery lifecycle. The choice of tooling for this transition has profound implications for an organization's agility, cost structure, and developer productivity. The analysis of Signadot, Okteto, vcluster, and the GitOps-native ArgoCD+Jenkins approach reveals four distinct architectural philosophies, each with a unique profile of strengths and weaknesses.
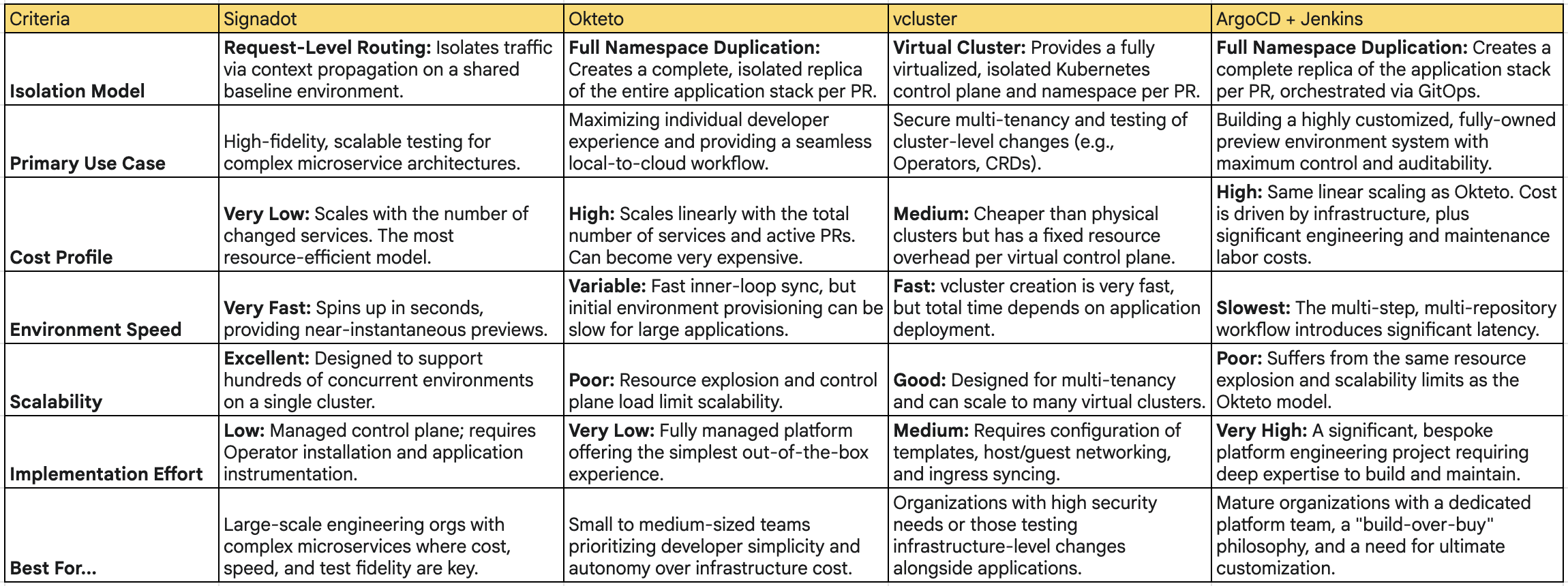
Comprehensive Tool Comparison Summary
The following table synthesizes the findings of the report, providing a high-level, comparative summary to aid in strategic decision-making.
Strategic Recommendations for Adoption
The optimal choice of tool is contingent on an organization's specific context. The following recommendations provide a strategic framework for this decision:
- Choose Okteto if... your organization's primary objective is to maximize individual developer productivity for a small-to-medium-sized team. It is the ideal choice when the application is of moderate complexity and the organization is willing to tolerate a higher infrastructure cost in exchange for unparalleled simplicity, a superior inner-loop development experience, and the conceptual ease of complete environment isolation.
- Choose vcluster if... your organization operates under stringent security, compliance, or multi-tenancy requirements. It is the superior solution when pull requests frequently involve changes that extend beyond the application layer to include cluster-level resources like Operators, CRDs, or complex network policies. It is the right choice for providing developers with "self-service" Kubernetes clusters that are strongly isolated from each other and the host infrastructure.
- Choose the ArgoCD + Jenkins approach if... your organization possesses a mature and well-resourced platform engineering team, fosters a strong "build-over-buy" culture, and requires ultimate control and customizability over its CI/CD and preview workflows. This path is for those who see their developer platform as a strategic, proprietary asset and have the long-term commitment to build and maintain a bespoke system.
- Choose Signadot if... your organization operates a complex, distributed microservices architecture where cost efficiency, scalability, and speed are critical business drivers. It is the forward-looking choice for high-velocity engineering teams that need to enable high-fidelity testing against real, stateful dependencies for every pull request. Signadot is the only model presented that makes this practice economically and logistically viable at the scale of hundreds of microservices, where traditional environment duplication is not a sustainable long-term strategy.
Concluding Remarks: The Future of Pre-Production Testing
The industry's trajectory is clear: the era of the slow, contentious, and monolithic staging environment is drawing to a close. The future of pre-production testing lies in dynamic, on-demand, and automated environments that are deeply integrated into the developer workflow. The evolution from simple duplication models to more sophisticated virtualization and request-level isolation techniques marks a significant advancement in the field. As organizations continue to embrace microservices and seek to accelerate their release cycles, the adoption of a robust preview environment strategy will cease to be a competitive advantage and will become a fundamental prerequisite for building and shipping high-quality software at speed and scale.



Join our 1000+ subscribers for the latest updates from Signadot

