Coding agents generate pull requests faster than anyone can review them, and open-source maintainers are the first casualties. The fix is not more review. It is moving validation into the development loop so every AI-generated change arrives with proof it works.
Open-source maintainers are the first people to feel what happens when generating code gets cheap and validating it does not. Every engineering leader rolling coding agents into their organization should be watching closely, because the same wave is heading for enterprise teams.
Over the past year, maintainers have been buried under AI-generated pull requests: verbose diffs with descriptions that do not match the code, contributions whose authors cannot answer a basic question about them, changes that read well and fall apart the moment anyone runs them.
The Jazzband collective, a large Python project ecosystem, shut down entirely this year. Its lead maintainer pointed to the unsustainable volume of AI-generated spam as a primary driver. Remi Verschelde, a maintainer of the Godot game engine, has described triaging AI slop as draining and demoralizing. Daniel Stenberg, the creator of curl, ended his project’s bug bounty after it became a magnet for low-effort AI submissions.
The shape of the problem is the same everywhere. Maintainers pour their time into evaluating code that should never have been sent, genuine contributions get crowded out, and burnout accelerates. Open repositories feel it first because anyone can point an agent at an issue and fire off a plausible-looking PR in seconds. But the imbalance underneath is not an open-source quirk. It is structural, and enterprise teams are walking straight into it.
The root cause is a throughput mismatch. Coding agents made producing code dramatically faster and cheaper. A developer working with an agent can open five or six pull requests in a day, and someone non-technical can generate working-looking code in minutes. What has not sped up at all is the review, validation, and integration of that code. Sixty percent of unpaid volunteer maintainers were already struggling to keep up before agents arrived. Now the volume has multiplied.
Coding agents made writing code cheaper and faster. The review, validation, and integration of that code did not get any faster.
As one contributor put it, if churning out code were all maintainers wanted, they could do it themselves. The value of a contribution was never the code on its own. It was the understanding behind it, the testing that backed it, and the human judgment that shaped it.
Inside a company the same problem just moves behind a corporate wall. When an organization mandates coding agents, it speeds up one end of the pipeline and leaves the other untouched. The reviewer inherits the entire job of working out whether a change actually runs, integrates cleanly, handles edge cases, and does not quietly regress something else. The data already shows the strain. Research from Agoda found experienced developers were 19 percent slower when using AI tools, much of it from what the researchers called comprehension debt: developers understand less of their own codebase over time as AI-written code accumulates. A CodeRabbit analysis of 470 open-source pull requests found roughly 1.7 times more issues in AI-co-authored PRs than in ones written entirely by humans.
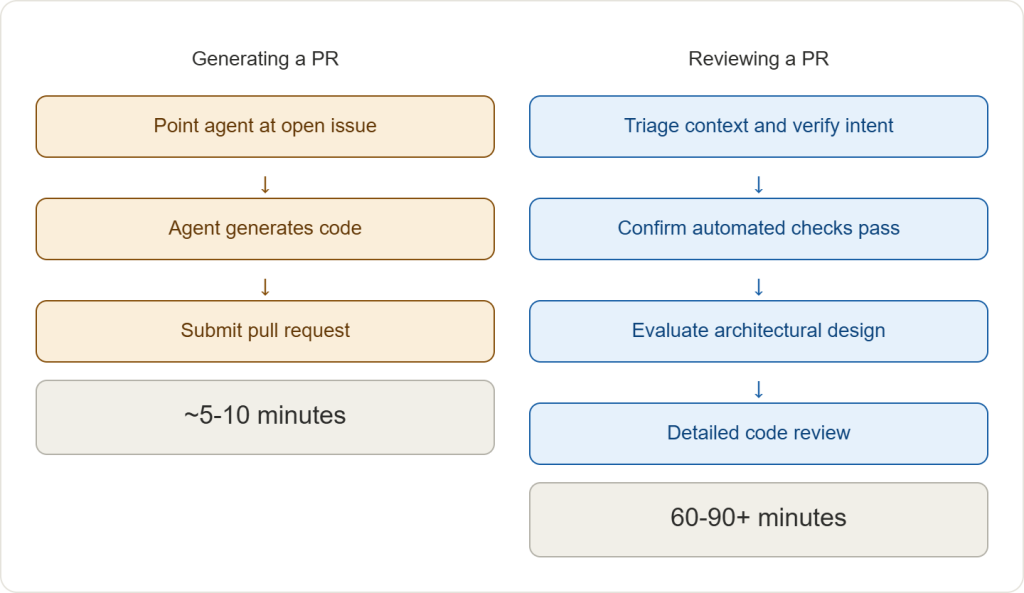
The arithmetic does not favor the reviewer, and it only gets worse as systems grow more complex.
The reflexive answer to a surge of AI-generated code is to throw AI-powered review at it. Tools that summarize pull requests, flag issues, and grade quality are multiplying fast. For straightforward changes they help: an AI reviewer can catch style violations, spot anti-patterns, and surface obvious bugs faster than a person reading line by line.
But for a cloud-native system with a dozen or more interdependent services, AI review hits the same wall as a traditional CI pipeline. Neither can tell you whether a change behaves correctly in context. A tweak to one service can look perfect in isolation while breaking a contract with a downstream consumer. An agent-written refactor can introduce a race condition that only shows up under realistic traffic. Answering those questions means running the code in something that resembles production, and no amount of static analysis, human or AI, is a substitute for that.
The validation gap sits earlier than most teams think, in the space between when code is written and when a reviewer can confidently judge it.
That gap is where the time disappears. If a developer ships six PRs a day and each one needs thirty-plus minutes of manual validation, they spend the day shepherding a queue instead of building software. The agent made writing fast. AI review made triage fast. Everything in between stayed slow.
Open repositories are absorbing the full, unfiltered force of cheap code generation because they cannot control who contributes. The projects that are coping best are not just bolting on stricter contributor policies and reputation systems. They are shifting the burden of proof back onto the contributor, asking for a demonstration that the code works rather than leaving the maintainer to prove that it does not.
Enterprise teams have the opposite balance. They have more control over who submits code and less insight into whether the person who submitted it actually understood it. An agent-generated PR from an internal engineer or a non-technical teammate looks identical in the review queue to a carefully crafted change from a senior developer. Without more context, the reviewer cannot tell the two apart, or quickly confirm that the code does what it claims.
The fix is to close the distance between generating code and validating it, so that every pull request arrives with evidence it works instead of a promise that it does.
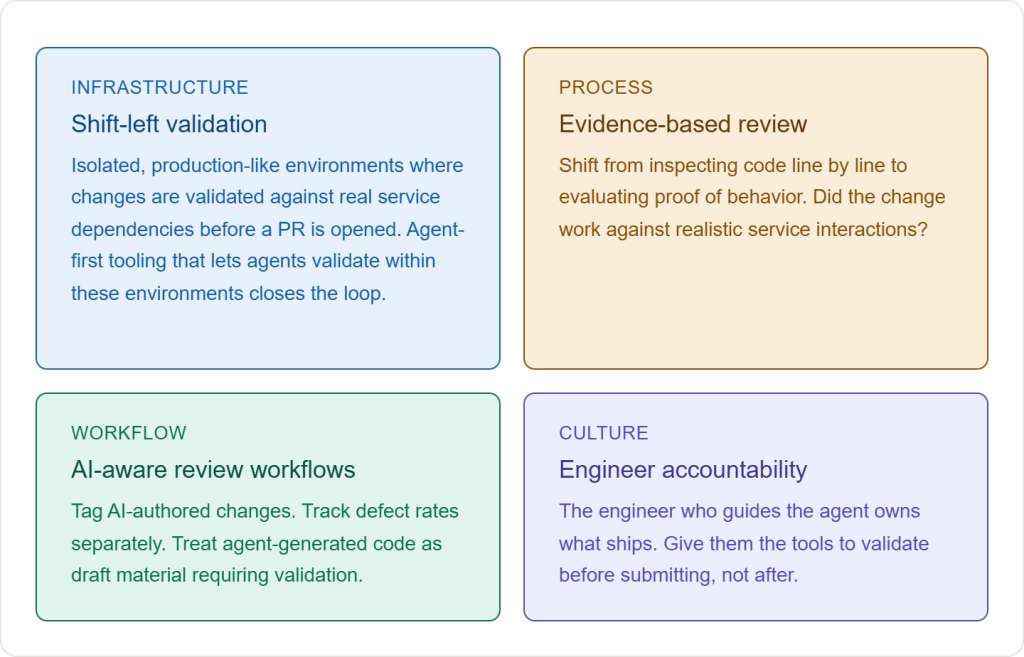
That takes a few shifts at once. Validation has to move into the development loop, where developers and agents can test a change against real service dependencies before the PR is ever opened. Review has to evolve from reading every line to evaluating evidence of behavior: did the change hold up against realistic service interactions, and does it match the spec. AI-generated code should be treated as draft material, tagged and tracked separately so its defect rate is visible rather than hidden. And accountability has to stay with the engineer guiding the agent, not the agent itself, which means handing that engineer the tools to validate agent-generated code inside the loop and submit with confidence instead of relying on a reviewer to catch the problems.
Closing the gap between generation and validation comes down to two capabilities, and they have to work together.
The first is an environment the agent can actually use. Spinning up the whole stack for every change is too slow and too expensive, and a laptop cannot hold a realistic version of a cloud-native system. The practical answer is request-level isolation: give each change its own sandbox that runs only the service being modified and shares a production-like baseline for everything else. The change runs against real dependencies, the sandbox is cheap enough to create on every pull request, and many can run in parallel on one cluster without colliding. This is the same model that fixes the staging bottleneck for human teams, and it is exactly what an agent needs to test its own work and keep going without waiting on a shared environment.
The second is a validation layer on top of that environment that turns “it ran” into “here is the evidence.” In Signadot that means SmartTests, which compare the changed service against the baseline and flag meaningful behavioral differences instead of relying on hand-written assertions; Jobs, which run the test suites you already trust against the sandbox; and Plans, which tie those checks into one repeatable workflow. An agent can run a plan against its sandbox, read the result, fix what broke, and attach the outcome to the pull request, so the change arrives with proof rather than a claim. We go deeper on this in our guide to validating AI-generated code on Kubernetes.
This is what actually shifts the burden of proof back to the contributor, human or agent. The reviewer stops re-deriving whether the code works and starts evaluating evidence that it does: did it pass against real dependencies, and does its behavior match the spec. It is also why AI-assisted review on its own is not enough. A reviewer bot reads the diff; a sandbox runs it. Pairing the two, behavioral evidence plus a smarter read of the change, is the only thing that scales to the volume agents now produce.
Open-source repos are the canary. Their openness means they take the full hit of cheap code generation first and most visibly. But the imbalance underneath, the speed of producing code racing ahead of the speed of validating it, is not theirs alone. It is structural, and it scales with every agent a company adopts.
Teams that pour investment into coding agents without matching it on the infrastructure to validate what those agents produce are building a pipeline that gets faster at creating work and no faster at finishing it. The PRs stack up, review times stretch, defect rates climb, and the engineers stuck reviewing agent output burn out for the same reasons open-source maintainers are burning out today.
The pieces to close the gap already exist: isolated preview environments, automated end-to-end validation, smarter review workflows, and real observability into agent-generated changes. Signadot is built to provide them, so teams can validate changes against real dependencies before the code ever reaches a reviewer. The organizations that put these capabilities in place before the backlog turns unmanageable are the ones that will get the speedup coding agents promised, instead of inheriting the crisis open source is living through right now.
Get the latest updates from Signadot

